
Coordinator reference
The Coordinator is a built-in agent (codename Squad) that every team gains automatically. It adds a single new capability on top of the existing single-agent platform: an orchestration layer. The coordinator turns a user goal into a confirmed, memory-informed outcome spec before any work begins.
The coordinator is itself an observable, streamed, human-accountable run (agent_name: "Coordinator", no parent run). It does not perform domain work itself — it only orchestrates and persists artifacts into the existing memory store.
This page documents the Phase 1 outcome-spec flow, the Phase 2 orchestration capabilities (decomposition, child dispatch, observation, topology events, and steering), and the Phase 3 collective assembly terminal-status surfaces (how a coordinator run reports its orchestration status and a human-readable reason on every terminal path).
Start contract and team requirement
POST /api/projects/{id}/orchestrations starts a coordinator run only after the project has a dispatchable cast team. The HTTP endpoint maps the guard into two explicit client contracts (apps/Agentweaver.Api/Endpoints/ProjectEndpoints.cs:429, :486):
| Status | Body | Meaning |
|---|---|---|
409 Conflict | { "error": "no_team", "message": "This project has no team. Cast a team before starting an orchestration." } | No active, dispatchable team member exists. |
422 Unprocessable Entity | { "error": "invalid_team", "message": "The project team roster could not be read. Fix the team before starting an orchestration." } | The roster could not be parsed/read. |
The guard reads the same .squad team source the dispatcher uses: EnsureDispatchableTeam calls SquadReader.ReadTeam, requires at least one member that is Active, has a non-null role, and passes the built-in-agent deny list (apps/Agentweaver.Api/Coordinator/CoordinatorRosterGuard.cs:30, :37, :54; apps/Agentweaver.Api/Coordinator/CoordinatorOrchestratorExecutor.cs:687, :750). Platform-owned Scribe, Ralph, RAI, and Build & Test roles do not count as worker capacity.
What it is (and is not)
The coordinator is orchestration-only. It MUST NOT reimplement any platform capability. The following capabilities stay owned by their existing features; the coordinator reuses them and never duplicates them:
| Capability | Owned by | Coordinator does |
|---|---|---|
| RAI gate | RAI reviewer in the run graph | Reuses it per run; never re-specifies RAI checks |
| Casting / roster / per-role model | Casting service | Selects agent + model per subtask (later phase) |
| Human review / merge | Run graph executors | Reuses them; never runs a parallel review or merge |
| Scribe / session logging | Scribe executor | Reuses it; never re-logs sessions itself |
| Memory and decisions | Memory store | Reads context; persists the outcome spec (and later the work plan); injects active decisions into child workers |
Because of this non-redundancy contract, the coordinator's charter describes only orchestration behavior — read memories and decisions for context, draft and confirm an outcome spec, and (in later phases) decompose, dispatch, observe, and hand off. It does not re-specify RAI, casting, memory governance, sandboxing, review, merge, or scribe. The provider is fixed to GitHub Copilot; only the model id varies within Copilot.
The Phase 1 outcome-spec flow
A coordinator run drafts a confirmable restatement of the goal and blocks all dispatch until a human confirms it.
- Start. A goal is submitted for a project. The coordinator run begins and emits
coordinator.startedcarrying thegoal. The project's working directory, default branch, and the authenticated caller become the run's repository path, originating branch, and submitting user. - Draft. The coordinator reads the project's existing memories and decision-inbox entries as grounding context, then drafts an outcome spec: a desired outcome, scope, assumptions, and any scoped clarifying questions. Drafting is roster/capability-aware and goal-breadth-faithful: the drafter reads the project's
.squadroster (dispatchable members only — Scribe, Ralph, RAI, and Build & Test are excluded) and injects a terseTEAM CAPABILITIESlist plus aSCOPE BREADTHinstruction so the drafted outcome enumerates the intermediate deliverables a full-journey goal asks for (e.g. research, PM, PRD, UX, build) while a narrow goal stays lean. The roster is only a capability filter; the goal's own words are the breadth driver, and the guidance is added outside the untrusted-goal fences (apps/Agentweaver.Api/Coordinator/CopilotCoordinatorSpecDrafter.cs:165,:205,:229). - Suspend at the gate. The outcome spec is persisted with status
awaiting_confirmation, and the run emitscoordinator.outcome_specand suspends at the confirmation gate. No decomposition or child dispatch occurs here — the run blocks until the human confirms or revises. - Confirm or revise.
- Confirm advances the spec to status
confirmed, emitscoordinator.outcome_spec.confirmed, and resumes the run. In Phase 1 the run then terminates (decomposition and dispatch are later phases), followed byrun.completed. - Revise re-drafts the spec using human feedback and re-suspends at the gate, emitting a fresh
coordinator.outcome_spec.
- Confirm advances the spec to status
Outcome spec fields
| Field | Notes |
|---|---|
goal | The submitted goal. |
desiredOutcome | The drafted desired outcome. |
scope | Drafted scope. |
assumptions | Drafted assumptions. |
clarifyingQuestions | Optional; omitted when none were drafted. |
status | drafting, awaiting_confirmation, confirmed, or declined. |
confirmedBy | Set once confirmed; omitted otherwise. |
The human confirmation gate
The gate is the safety property of the flow: no subagent work is dispatched before a human confirms the outcome spec. A named human stays accountable for the run. The gate is reachable from both mandated clients at parity:
- Web UI — the coordinator run page renders the outcome-spec panel with Confirm and Request-changes actions and an explicit "no work is dispatched until you confirm" notice. See the Web UI reference.
- MCP server — the
coordinator_*tools start, read, confirm, and revise the spec;run_watchon the coordinator run id streams the live drafting. See the MCP server reference.
Both clients are thin: all orchestration logic lives in the API's coordinator service, and clients hold no spec logic.
Web client edge states are intentionally visible. Before the coordinator has persisted the draft, GET /api/runs/{id}/outcome-spec may return a transient 404; OutcomeSpecPanel keeps rendering a Drafting state and polls every 2 seconds until the draft arrives, unless the run reaches a terminal failure first (apps/web/src/components/OutcomeSpecPanel.tsx:160, :233, :328, :401). Confirm is guarded with an in-flight ref plus disabled actions and a Confirming... label; it retries only the short 409 no_pending_gate gate-arming race and otherwise surfaces 409/non-active errors after refreshing the spec (OutcomeSpecPanel.tsx:237, :338, :345, :360, :578).
Phase 2 orchestration
Confirming the outcome spec carries the coordinator run through Phase 2: confirm -> select workflow -> decompose -> dispatch -> observe -> steer. No work begins before confirmation, so the Phase 1 gate stays the single safety property.
Workflow selection: how the coordinator picks the process to run
Before it decomposes anything, the coordinator decides which workflow (which run pipeline) the work should follow. The selection algorithm is CoordinatorOrchestratorExecutor.SelectWorkflowAsync (apps/Agentweaver.Api/Coordinator/CoordinatorOrchestratorExecutor.cs). It is deterministic-first: hard rules narrow the candidate set, and an LLM is consulted only as a last step when more than one candidate genuinely fits.
The algorithm runs in this order:
- Resolve the project default first.
WorkflowRegistry.ResolveDefault(project)produces the project's effective default (the project'sDefaultWorkflowIdwhen valid, else the built-indefault). It is held as the deterministic fallback this method returns whenever a later step throws or nothing is eligible. - Build the available list.
WorkflowRegistry.GetOrLoad(project).Available(validation-passing workflows) is ordered default first, then by id (StringComparer.Ordinal). The first entry is, by convention, the deterministic fallback for the selector. - Resolve the invocation kind.
ResolveInvocationKindAsyncmaps the run's origin to aWorkflowInvocationKind: a run stampedRunOrigin.BacklogPickup(the heartbeat picked up a Ready task) becomesWorkflowInvocationKind.Heartbeat; every other origin — and any lookup failure — becomesWorkflowInvocationKind.Manual. - Honor a request-level or backlog task override (if eligible). The
StartOrchestrationRequest.workflow_override_id(dialog override) takes precedence over the backlog task pin. If either carries aWorkflowOverrideId, that workflow is used only if it exists in the available set and its trigger is eligible for this invocation (WorkflowTriggerEvaluator.IsEligible). An unavailable or trigger-ineligible override is logged and ignored, and selection continues. - Filter by trigger eligibility. The available list is reduced to workflows whose declared trigger matches the invocation kind via
WorkflowTriggerEvaluator.IsEligible. - No eligible candidate → project default. If nothing passes the trigger filter, the project default is returned (never a trigger-mismatched workflow).
- Exactly one eligible candidate → use it. A single eligible workflow is used directly, with no model call and no selection event.
- Multiple eligible candidates → resolve the pick. A
WorkflowSelectionContextis built (project id, goal, roster role titles, the eligible definitions, and the set of custom/project workflow ids). Then:- An explicit human override
use <workflow-id>in the latest revise feedback wins (WorkflowSelector.TryParseOverride); the chosen workflow is returned and a selection event is emitted (wasAutoSelected: false). - Otherwise the LLM-backed
WorkflowSelector.SelectAsyncpicks by process fit; the result (and its rationale) is returned and a selection event is emitted (wasAutoSelected: true).
- An explicit human override
Trigger taxonomy (apps/Agentweaver.Api/Workflows/WorkflowDefinition.cs)
Every workflow declares exactly one WorkflowTrigger { Type, Event }:
WorkflowTriggerType | Meaning | Eligible for |
|---|---|---|
Manual | A person or client explicitly starts the run. | Manual invocations only. |
Heartbeat | The coordinator heartbeat picks up Ready work. | Heartbeat invocations only. |
Event | The workflow starts on a declared WorkflowEventType. The only supported event is TaskAddedToReady. | Heartbeat invocations (a task entering Ready is that event). |
Trigger filtering (apps/Agentweaver.Api/Workflows/WorkflowTriggerEvaluator.cs)
WorkflowTriggerEvaluator.IsEligible(trigger, kind) is the hard boundary applied before any model call:
Manualinvocation → onlyManual-trigger workflows.Heartbeatinvocation →Heartbeat-trigger workflows orEvent-trigger workflows whose event isTaskAddedToReady.
WorkflowTriggerEvaluator.Filter preserves input order, so the default-first ordering survives filtering.
Override mechanisms
| Channel | Source | Resolution |
|---|---|---|
| Dialog override | StartOrchestrationRequest.workflow_override_id, set in the Start task dialog. | Step 4: checked first, before the backlog task pin. Used only when the workflow exists and is trigger-eligible. |
| Backlog task override | BacklogTask.WorkflowOverrideId, set before pickup. | Step 4: used when no dialog override is present. Used only when the workflow exists and is trigger-eligible. CoordinatorPickupService additionally prepends use <id> to the goal text so the conversational path also sees it. |
| Conversational override | A human message matching use <workflow-id> in the revise feedback. | Step 8: WorkflowSelector.TryParseOverride matches the pattern; the requested workflow wins if it is among the eligible candidates. |
Precedence order (highest to lowest): dialog override → backlog-task pin → conversational use {workflow-id} → LLM auto-select → project default.
An override never escapes the candidate safety boundary: it cannot run a workflow the registry cannot resolve or the trigger evaluator rejects.
The LLM selector and its fallbacks (apps/Agentweaver.Api/Coordinator/WorkflowSelector.cs)
WorkflowSelector.SelectAsync is reached only with two or more eligible candidates and no explicit override:
- If
AvailableWorkflows.Count == 1it returns the default with no model call. - Otherwise it builds a process-fit prompt and calls
IWorkflowSelectionModel.CompleteAsync. The production implementation isCopilotWorkflowSelectionModel, a Copilot completion wrapper whose failures returnnull. - The model must reply with JSON
{ "selected": "<id>", "rationale": "<why>" }. Anull/unparseable response, an unknown id, or a thrown exception all fall back deterministically to the first candidate (the project default), with a rationale that explains the fallback.
Whenever the multi-candidate path runs, the coordinator emits a coordinator.workflow_selected event (EmitWorkflowSelectedEvent) carrying selectedId, selectedName, rationale, wasAutoSelected, an overrideHint (Reply 'use {other-id}' to change...), and the list of available workflows. If SelectWorkflowAsync throws anywhere, it logs a warning and returns the resolved project default so the caller always knows which workflow it is planning against.
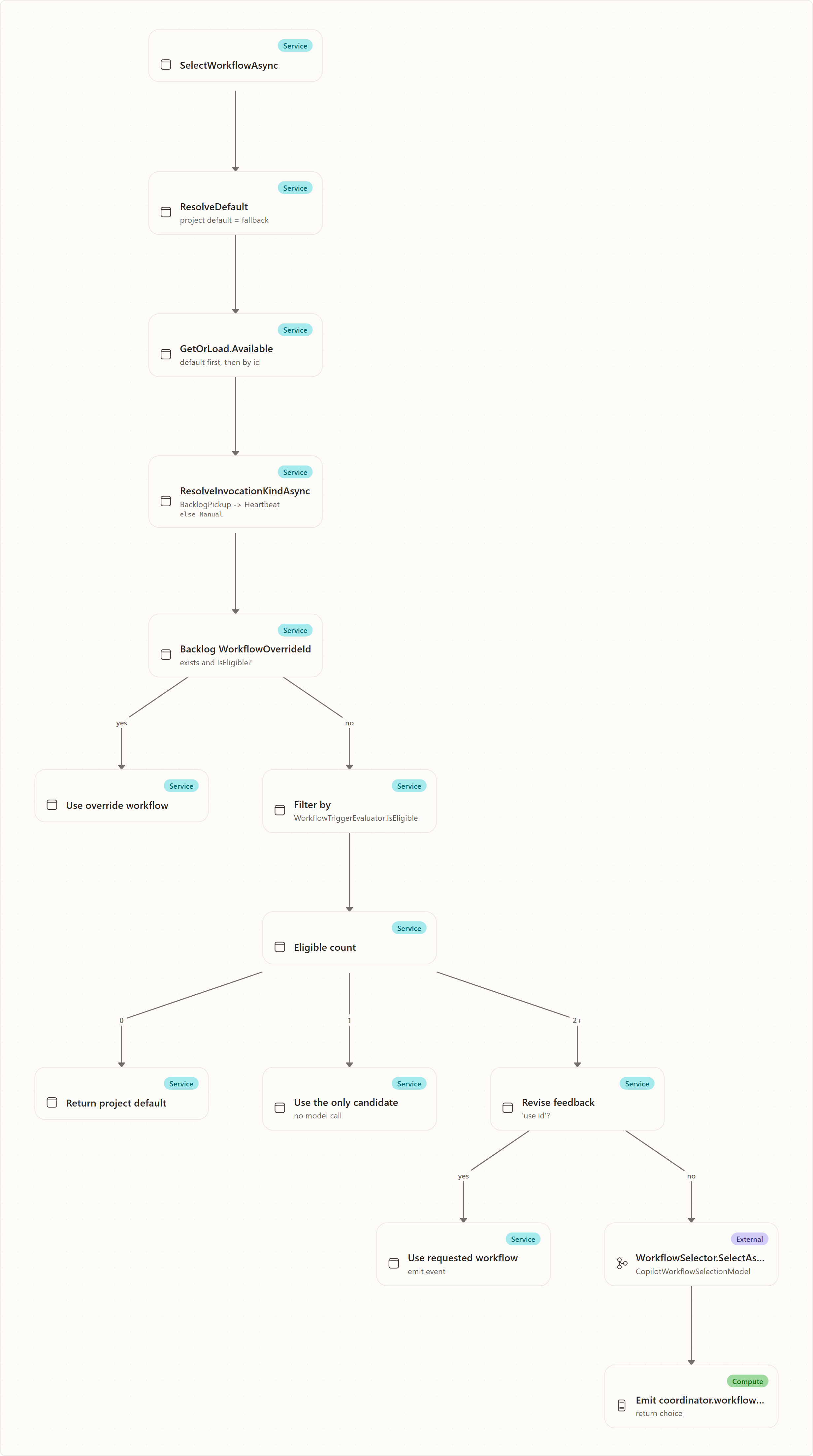
The selected workflow is not only recorded for display: it becomes prompt context for decomposition so the resulting subtask graph mirrors the intended process shape. The run workflow factory later resolves the effective workflow again when it builds the executable graph, so a stale planning pick can never become unchecked runtime execution.
Decomposition and the work plan
After confirmation, the coordinator decomposes the spec into a work plan: a set of subtasks plus the dependency edges between them. Each subtask carries an assigned roster agent (selected for role fit), a selected model (within the GitHub Copilot provider), a phase, an isolation, and a status. The plan is persisted to the memory store and emitted as coordinator.work_plan. Subagents read the confirmed spec and plan from the memory store; the coordinator does not introduce a parallel store. Read it over HTTP with GET /api/runs/{id}/work-plan or over MCP with coordinator_work_plan_get.
Model selection precedence (per subtask). A non-empty run model pin — the run's explicit modelId on POST /api/projects/{id}/orchestrations, or (when no explicit id is passed) the project's GitHub Copilot default — is selected for every subtask regardless of complexity; otherwise the subtask uses its assigned role's default model, then a catalog role default, then the configured Copilot default. The configured Copilot default is CoordinatorModelDefaults.DefaultCopilotModel = "claude-sonnet-4.6" (apps/Agentweaver.Api/Coordinator/CoordinatorModelDefaults.cs), overridable via the Providers:GitHubCopilot:Model config key. The stale hardcoded gpt-4o last-resort fallback was removed; the constant is the single source of truth for the last-resort default. The same precedence is preserved when a reviewer rejection rotates a subtask to a different eligible author (the pin wins over the rotated author's role default).
Behavior change
A non-empty run model pin now pins all subtasks (previously only high-complexity subtasks adopted the run's explicit model). Two consequences follow: (a) a well-formed but nonexistent pinned model id now affects every subtask (not just high-complexity ones); and (b) setting a project GitHub Copilot default disables per-role model differentiation for that project's runs — leave both the explicit modelId and the project default unset if you want subtasks to use their individual role-default models.
Run model pin: UI behaviour
In Project Settings → Default run model, the field is free-text. Leaving it empty means "Auto (coordinator picks)" — the coordinator selects a model per task using per-role defaults; subtasks may use different models. Entering a model id pins every subtask in every run for this project to that single model.
Model catalog (current)
Model ids are free-text passthrough to the GitHub Copilot CLI. They are validated only by a permissive prefix regex (^(gpt|claude|o)...) — there is no hardcoded allowlist, so new models become available as GitHub Copilot publishes them without a server update. The currently documented catalog:
| Family | Model ids |
|---|---|
| OpenAI GPT | gpt-5.6-sol, gpt-5.6-terra, gpt-5.6-luna, gpt-5.5, gpt-5.4, gpt-5.3-codex, gpt-5.4-mini, gpt-5-mini |
| Claude | claude-opus-4.8, claude-opus-4.7, claude-opus-4.6, claude-sonnet-5, claude-sonnet-4.6, claude-sonnet-4.5, claude-haiku-4.5 |
A well-formed but unavailable id at runtime causes a classified provider error (AgentProviderException, kind UnavailableModel). The coordinator's last-resort default is claude-sonnet-4.6.
The WorkPlan row also carries CoordinatorPodId, the distributed lease owner for dispatching. When a pod starts or re-arms dispatch, it atomically stamps this field and refreshes UpdatedAt; other replicas skip the plan while that claim is fresh and only try to steal it after Coordinator:PodLeaseStaleTtlSeconds (default 120 s). While a pod owns a dispatch loop it renews the lease every Coordinator:PodLeaseHeartbeatSeconds (default 30 s) from an independent timer, so a long child turn cannot let the lease age into staleness and let a peer start a second loop. This prevents multiple replicas from re-arming the same dispatch loop at once. See coordinator internals for the heartbeat, fencing, and the per-project integration-branch build lock.
When no catalog/roster role adequately covers a subtask's function, the decomposition MAY mint a bespoke role: a descriptive id plus a short inline charter (2–4 sentences defining the agent's persona, expertise, and approach). Bespoke roles are a last resort — the decomposition prompt prefers exact catalog/roster ids and only sets a subtask's charter field when the role is bespoke. A subtask's inline charter is persisted on the subtask and flows to the dispatched child run's AgentCharter, overriding file-based charter resolution so the coordinator can stand up a domain-specific persona without a catalog role.
The isolation field (worktree | shared) is an advisory hint only with no runtime enforcement — every child run executes against a single shared worktree. Each subtask must therefore declare its output filename(s) in its scope so the assembly conflict check can serialize colliding writers.
Child dispatch: parallel and serial
The coordinator dispatches subtasks as first-class child runs parented by the coordinator run, reusing the existing single-agent run machinery (sandboxing and step streaming) rather than new run primitives. Dispatch is dependency-ordered:
- Subtasks with no unmet dependencies dispatch together and run in parallel.
- A subtask with a dependency does not start until every prerequisite reaches
assemble_ready/completed, so dependent work runs serially behind it. - A failed, blocked, or RAI-flagged predecessor does not satisfy a dependency, so its dependents stay blocked.
Each child worker is dispatched with its charter (catalog or bespoke inline charter) plus the project's active architectural/scope decisions — compiled by MemoryContextCompiler.CompileDecisionsAsync and injected as the ## Boundaries and Decisions block. Children deliberately do not receive the full four-layer memory stack (core context, learnings, session), which duplicated the charter and carried artifact-write instructions that broke inside a child worktree; only the non-negotiable decisions reach them, ensuring scope constraints bind the agents doing the actual work. See the Memory reference.
A subtask's status advances pending -> dispatched -> running -> {assemble_ready | rai_flagged | completed | failed}, surfaced as subtask.* events. The dispatcher can also mark a pending dependent blocked when an upstream prerequisite stalls and therefore never satisfies its dependency. The dispatched child runs (paired with subtask status) are available from GET /api/runs/{id}/children or the coordinator_children_get MCP tool.
Subtask status enum
The persisted subtask status values are:
| Status | Meaning | Satisfies dependencies? | Terminal? |
|---|---|---|---|
pending | Planned and waiting for its dependencies and conflict checks. | No | No |
dispatched | Child run was created and handed off. | No | No |
running | Child run is actively executing. | No | No |
pending_capacity | Legacy / historical. Kubernetes now owns pod admission and scheduling, so new runs never enter this status (issue #217). A pre-upgrade subtask stranded here is recovered to pending and re-attempted. | No | No |
assemble_ready | Child finished with mergeable changes ready for collective assembly. | Yes | Yes |
completed | Child finished with no further mergeable changes required. | Yes | Yes |
rai_flagged | Child hit a responsible-AI block. | No | Yes |
failed | Child ran but ended unsuccessfully. | No | Yes |
blocked | The subtask never ran because an upstream dependency stalled, so the coordinator terminalized it as ineligible. | No | Yes |
A stall is not immediately terminal. When a child stalls, the coordinator redispatches the subtask on a fresh child/pod up to CoordinatorSteeringService.MaxRecoveryAttempts (3) times — emitting coordinator.subtask_redispatched and incrementing the monotonic RecoveryAttempts each time — before the stall becomes a terminal failed and its dependents cascade to blocked (apps/Agentweaver.Api/Coordinator/CoordinatorDispatchService.cs:399, :1235). See the coordinator deep-dive stall redispatch before dead-end.
Observation and topology events
The coordinator observes each child through its read-only run timeline and projects two views onto its own run stream:
subtask.*events — the granular per-subtask lifecycle (subtaskId,childRunId,assignedAgent,selectedModelId,status).coordinator.topologyevents — the orchestration graph. Aversion: 1snapshot (seq: 0) carries every node (one coordinator node plus one per subtask) and the dependency edges; deltas (seq > 0) carry only the changed node(s). Edge direction is always dependency to dependent, and edges never change after the snapshot.Each node carries an
executionPodNamefield:- Coordinator node — the Kubernetes pod name of the API process, or
nulloutside Kubernetes. - Subtask node — the pod name of the child run's bound AgentHost pod (from
IPodNameRegistrykeyed bychildRunId), ornullwhen the subtask has not been dispatched or the pod has not been bound yet.
A
nullexecutionPodNamemeans no execution pod is assigned to that node. The UI shows a pod chip only when the value is non-null; it does not fall back to the API pod name for child or intermediate nodes.- Coordinator node — the Kubernetes pod name of the API process, or
Because these events ride the coordinator run's ordinary event stream, the live graph is fully reconstructable from a single stream. Over MCP, point run_watch at the coordinator run id; there is no separate streaming tool. orchestration_topology (or the work-plan plus children endpoints) gives a one-shot snapshot when a point-in-time view is enough.
Steering verbs
A user steers the coordinator while subagents run or while the coordinator is parked at collective human review. GET /api/runs/{id} exposes coordinator_steerable: true for coordinator runs in in_progress or awaiting_review, and the web client uses that field to keep the coordinator message composer enabled during review (apps/Agentweaver.Api/Contracts/Dtos.cs:178, apps/Agentweaver.Api/Coordinator/CoordinatorSteeringService.cs:348, apps/web/src/api/types.ts:81). The coordinator relays direction to targeted child run(s) via POST /api/runs/{id}/steer or the coordinator_steer MCP tool. The verbs carry the following semantics:
| Verb | Effect | Timing |
|---|---|---|
send | Delivers an informational message or note to the coordinator without changing the chosen direction. | Queued and delivered at the next safe boundary; if collective assembly is blocked, it wakes the coordinator and retries assembly with the new context. |
stop | Cancels the targeted child run's in-flight turn. | Immediate. |
redirect | Relays new direction the subagent applies as a revised task turn. | At the subagent's next turn boundary; no restart. |
amend | Relays an adjustment the subagent folds into its next turn. | At the subagent's next turn boundary; no restart. |
An in-flight agent turn cannot be interrupted mid-turn under the run model, so only stop reaches a subagent during a turn. send, redirect, and amend are queued and applied when the child's current turn completes (or when it next suspends at a gate), without restarting the run. The queue is DB-backed and replica-safe: a queued directive transitions queued -> relayed under a compare-and-swap so a mid-run message is delivered exactly once even across API replicas. stop bypasses the queue entirely — it is the only hard interrupt. Omitting the target broadcasts to every active child. Directives progress through coordinator.steering events (pending -> queued -> relayed -> applied, plus deferred at the review gate).
At the assembly human-review gate (#226). When the coordinator is parked at collective review (awaiting_review, coordinator_steerable: true), a redirect/amend/send is delivered to the parked assembly loop rather than the child-turn queue (previously it was accepted as queued and then silently dropped). redirect/amend are translated into a request-changes review decision — the same path as POST /assembly/review {request_changes} — re-dispatching the implicated subtasks (#223 scoping) with an unconditional steering-budget reset and settling relayed; send posts an advisory note without changing the gate and settles applied. By default the change re-engages all contributors; set targetChildRunId to narrow to that subtask and its co-touching subtasks. If the gate is armed on another replica the decision is durably deferred for the owner's poller, the directive settles deferred, and POST /steer returns 202 Accepted instead of 201 Created. See resilient assembly review.
Pause is not supported. No hold-before-next-turn primitive exists in the run model; the steering surface is send, stop, redirect, and amend only. Pause is deferred to a later phase.
Asking the human: ask_question
Agents do not silently guess when they hit a material decision or an action that needs permission. They call the ask_question(question) tool, which suspends the agent and bubbles the question to a human (see events.md for the event/endpoint mechanics).
- During decomposition, the coordinator itself calls
ask_questionto clarify ambiguous scope or plan details with the user before finalizing the work plan, then proceeds once it has the answer. - For running children, the coordinator's child watcher re-projects each child's
agent.question_askedonto the coordinator stream ascoordinator.child_question, and each child'stool.approval_requiredascoordinator.child_approval_required, attributing both to the originatingchildRunIdandsubtaskId. The accountable human answers the question against the child run (POST /api/runs/{childRunId}/questions/{requestId}/answer) and grants/denies the gated action via the child run's tool-approval endpoints. Re-projection runs alongside the terminal-event mapping and does not change it.
Per-run options: Autopilot and auto-approve-tools
Two per-run boolean options, both default OFF, can be set at launch (autopilot and autoApproveTools on POST /api/projects/{id}/orchestrations) and toggled live (POST /api/runs/{id}/autopilot and POST /api/runs/{id}/auto-approve, body { "enabled": bool }). Both are held in an in-memory per-run options store and cascade to every child the coordinator dispatches (the child inherits the coordinator's flags at dispatch). They are distinct opt-ins and do not imply one another.
Autopilot does two things, both of which are on or off together:
- Auto-answers clarifying questions. A
coordinator.child_question(or a question asked directly on the coordinator run) is answered by the coordinator model from the outcome spec + subtask context, and the answer is resolved on the question gate (IQuestionGate.Answer(childRunId, requestId, answer)). Each auto-answer is logged ascoordinator.autopilot_answered { runId, childRunId?, requestId, question, answer }, and the normalagent.question_answeredresolution still surfaces on the child stream, so the timeline shows every auto-answer. - Auto-confirms the outcome spec. When a run starts with autopilot=true in
defineOutcomemode,StartCoordinatorRunAsyncschedules a boundedScheduleUnattendedConfirmloop that waits for the spec to reachawaiting_confirmationand then confirms it unattended, with no human gate. For an interactivePOST /api/projects/{id}/orchestrationslaunch the confirmation is attributed to the submitting user (confirmedBy= the authenticated caller); for a backlog pickup run it is attributed to the accountable human captured on the backlog item. When autopilot=false, the run pauses atawaiting_confirmationand a human must confirm (or revise) via the UI before any work begins.direct-mode runs have no confirmation gate at all, so autopilot schedules no confirm loop for them.
Autopilot NEVER auto-grants tool approvals or permissions; those still go to the human. The
PickupAutopilotproject flag defaults totrue, so existing projects retain the prior auto-confirm behavior unless the setting is turned off.- Auto-answers clarifying questions. A
auto-approve-tools auto-grants allow-with-approval tool requests (for example
web_fetch) at the human-in-the-loop gate, logging each astool.auto_approved { requestId, toolName, url? }. It NEVER overrides a policy deny: dangerous tools are rejected upstream by sandbox governance before the approval gate is reached, so the auto-grant only short-circuits the HITL wait for tools that are already allowed-with-approval.
Phase 3 collective assembly and terminal status
After every child subtask finishes, the coordinator runs ONE collective assembly: it builds a single integration branch (all eligible child branches merged in dependency order off the originating branch), then runs the selected workflow's assembly gates in happy-path traversal order. For software workflows that path places RAI before Build & Test and human review. The RAI reviewer returns a machine-readable VERDICT: <GREEN|YELLOW|REVISE|RED> sentinel as the last line of its response — only that line is parsed as the decision (prose is never scanned), and an unparseable verdict fails safe to a blocking RED after exactly one bounded re-ask (reason unparseable_after_reask), so a benign review can no longer be false-escalated by a legend echo (apps/Agentweaver.Api/Coordinator/CollectiveAssemblyPipeline.cs:88, packages/Agentweaver.AgentRuntime/Workflow/RaiTurnExecutor.cs:183). When the integration has changes, the RAI and Rubberduck reviewers read the actual assembled files through one shared detached worktree checked out at the integration tip (reusing the Build/Test worktree name), not just the aggregate diff text (apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:785, apps/Agentweaver.Api/Coordinator/CollectiveAssemblyPipeline.cs:298). Build & Test is an automated platform gate over a detached integration-branch worktree; in Sandbox:AgentExecutionMode=pod-per-run, it binds a dedicated AgentHost sandbox pod to the coordinator run id and configures that pod to use the detached worktree as its working directory before running the turn (apps/Agentweaver.Api/Coordinator/CollectiveAssemblyPipeline.cs:155, apps/Agentweaver.Api/Sandbox/KubernetesSandboxExecutor.cs:300). After Build & Test returns approved or request-changes, the deterministic PreviewStep starts the app, observes the actual port, and emits sandbox.preview_ready, sandbox.preview_failed, or sandbox.preview_skipped_not_applicable; preview failure never changes the verdict or blocks human review (apps/Agentweaver.Api/Coordinator/Preview/PreviewStep.cs:70, apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:753). Human review is the only gate that accepts POST /api/runs/{coordinatorRunId}/assembly/review. On approve it merges, runs the collective scribe, and completes. Request-changes feedback from human review, RAI, Rubberduck, Build & Test, agents, the coordinator, or a workflow step now flows through unified steering: coordinator.steering_received records the source and coordinator.steering_decision records whether the coordinator chose in-place steering, fresh dispatch, proceed/terminal, or advisory no-op before any effect executes (apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:1680, apps/Agentweaver.Api/Coordinator/CoordinatorSteeringDecider.cs:201). The separate Assembly Gate route was removed in favor of this coordinator-owned steering path. Sandbox infrastructure failures are classified separately as build_test_infra_*: retryable cases park as assembly_blocked, and non-retryable configuration errors fail assembly. Their event payloads include detail, exceptionMessage, innerExceptionMessage, innerExceptionType, and infrastructureReason, so /api/runs/{id}/events shows the underlying AgentHost launch or transport failure instead of only the generic reason (apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:1590, :1604). The review POST is replica-safe: a non-owner API replica can persist a deferred decision while the work plan is durably in_review, and the owner pipeline consumes it at most once. See Decoupled live-preview provisioning, Unified steering, and the events reference.
When assembly stops with coordinator.assembly_blocked, the payload always includes workPlanId and reason. For the ineligible_subtasks path it also includes:
ineligibleSubtaskIds— the blocking subtask ids, preserved as the stable compact list for clients.ineligibleSubtasks— enriched rows withid,title,status,agent, andrecoveryGuidanceso the UI can explain which subtasks blocked collective assembly and why.
This is the no-partial-assembly gate: if any subtask is still ineligible, including blocked, the coordinator stops before collective review or merge.
For retryable Build & Test infrastructure blocks, coordinator.assembly_blocked is a recoverable stream event, not a terminal stream event. Subscribers remain attached so they can see the subsequent re-arm/recovery path. coordinator.assembly_failed is terminal, but the durable stream drains all persisted replay rows before ending the SSE subscription, so diagnostics emitted around terminalization are still visible (apps/Agentweaver.Api/Infrastructure/SqliteRunEventStream.cs:153, apps/Agentweaver.Api/Infrastructure/EfRunEventStream.cs:111).
A coordinator run stays in_progress for the whole dispatch-plus-assembly window (its stream stays open), so the bare RunStatus is not enough for a UI to describe where the orchestration is. Two surfaces fix this:
coordinator_status— the currentWorkPlan.Status(dispatching,awaiting_assembly,assembling,in_review,complete,assembly_blocked,assembly_failed,assembly_declined) is added to each coordinator run onGET /api/projects/{id}/runsandGET /api/runs/{id}. It isnullfor normal runs. The UI renders this (for example "Awaiting assembly", "In review") instead of the barestatus.coordinator_steerable—trueonGET /api/runs/{id}for coordinator runs whose parent run status can still accept operator messages:in_progressandawaiting_review. This keeps steering and free-form coordinator messaging available while the assembly human-review gate is open.- Terminal status with a reason — every terminal assembly path moves the coordinator run to a terminal
RunStatusAND records a human-readableresult(the reason):assembly_blocked: <reason>(Failed),assembly_merge_failed: <reason>(MergeFailed),assembly_declined(Declined),assembly_error: <message>(Failed, unexpected fault in the assembly background task), orassembly_complete(Completed). The work plan moves to a matching terminalWorkPlanStatusso the topology coordinator node reflects it. The sameresultis exposed asstatusReasononGET /api/runs/{coordinatorRunId}/work-plan. A user is never left with a bare "Failed" and no next action.
Surviving a process restart
A coordinator run stays InProgress across the dispatch-plus-assembly window, which is driven by in-memory background loops (D3 — service-driven, not a MAF graph). The orchestration nevertheless survives a process restart on any replica, because all of its state is persisted in the relational store (WorkPlan.Status / AssemblyStage / IntegrationBranch, Subtask rows, and child Run rows) — the loops are just drivers that can be reconstructed from that projection.
On startup, after the generic restart sweep has failed any stranded child runs, CoordinatorRunService.RecoverInterruptedRunsAsync reconstructs each interrupted coordinator run by routing on its persisted work-plan status:
| Work-plan status | Recovery action |
|---|---|
| (no work plan) | Resume the checkpointed MAF spec workflow from its checkpoint so the user can still confirm/revise. |
planned, dispatching | Reset in-flight subtasks (dispatched/running) back to pending and re-arm the dispatch engine — re-launching fresh child runs for them. Terminal subtasks (assemble_ready/completed/failed/rai_flagged) and their child branches are preserved. |
awaiting_assembly | Re-arm the collective-assembly engine; the DB CAS (TryStartAssemblyAsync) claims it exactly once. |
assembling, in_review | Reset the plan to awaiting_assembly and re-run the (idempotent) assembly core — it rebuilds the integration branch and re-arms the human-review gate. Review decisions submitted to a different replica during the review window are held as deferred decisions and consumed by the owner pipeline after the gate is armed. |
complete / assembly_* | Settle the run row to its matching terminal RunStatus (a crash between the plan write and the run finalize). |
The recreated run emits coordinator.recovered and the re-armed engine re-emits its topology / assembly snapshots, so the live view renders immediately on reconnect. Every engine entry point is idempotent (in-memory guard + DB CAS), so re-arming is safe.
Related references
- Workflow selection — Deep Dive — concept, end-to-end algorithm, and mermaid flow for the full selection + override hierarchy
- API reference — Coordinator endpoints
- API reference — The orchestration lifecycle
- Events reference —
coordinator.*andsubtask.*events - MCP server reference — Coordinator tools
- Web UI reference — Coordinator orchestration and topology view
- Web UI reference — Coordinator run and outcome-spec gate
- Browser console reference
- Project generation model settings