
Coordinator Internals — Conceptual Deep Dive
Purpose and scope
The orchestration overview explains how a goal moves through Agentweaver at a system level. The focus here is the coordinator itself: the subsystem that turns one broad request into a confirmed intent contract, a dependency-aware work plan, multiple child runs, and one collective result.
The coordinator is best understood as a durable team manager. It does not merely ask a model to "do the task." It records what success means, decides how to divide responsibility, starts child workers only when their prerequisites are ready, watches their outcomes, assembles their branches into one candidate result, and routes failure back into retry or terminal states.
Primary scope:
- outcome-spec drafting and confirmation;
- workflow selection and work-plan decomposition;
- subtask dispatch, observation, bubbling, and steering;
- collective assembly, review, merge, and scribe;
- restart recovery and retry semantics.
For the high-level relationship between coordinator orchestration and run workflow orchestration, see Orchestration Engine — Conceptual Deep Dive. The sections below assume that overview and go deeper into the coordinator's own internal logic.
The coordinator mental model
A coordinator run has two personalities:
- Model-assisted planner. It drafts an outcome spec, optionally revises it, selects a workflow shape, and decomposes the confirmed intent into subtasks.
- Service-driven supervisor. After planning, background services drive dispatch and assembly from persisted state. They do not need the planner workflow to stay alive.
That split is the key to rebuilding the subsystem. The model helps create structured intent and plan data. Durable services then advance that data through deterministic state machines.
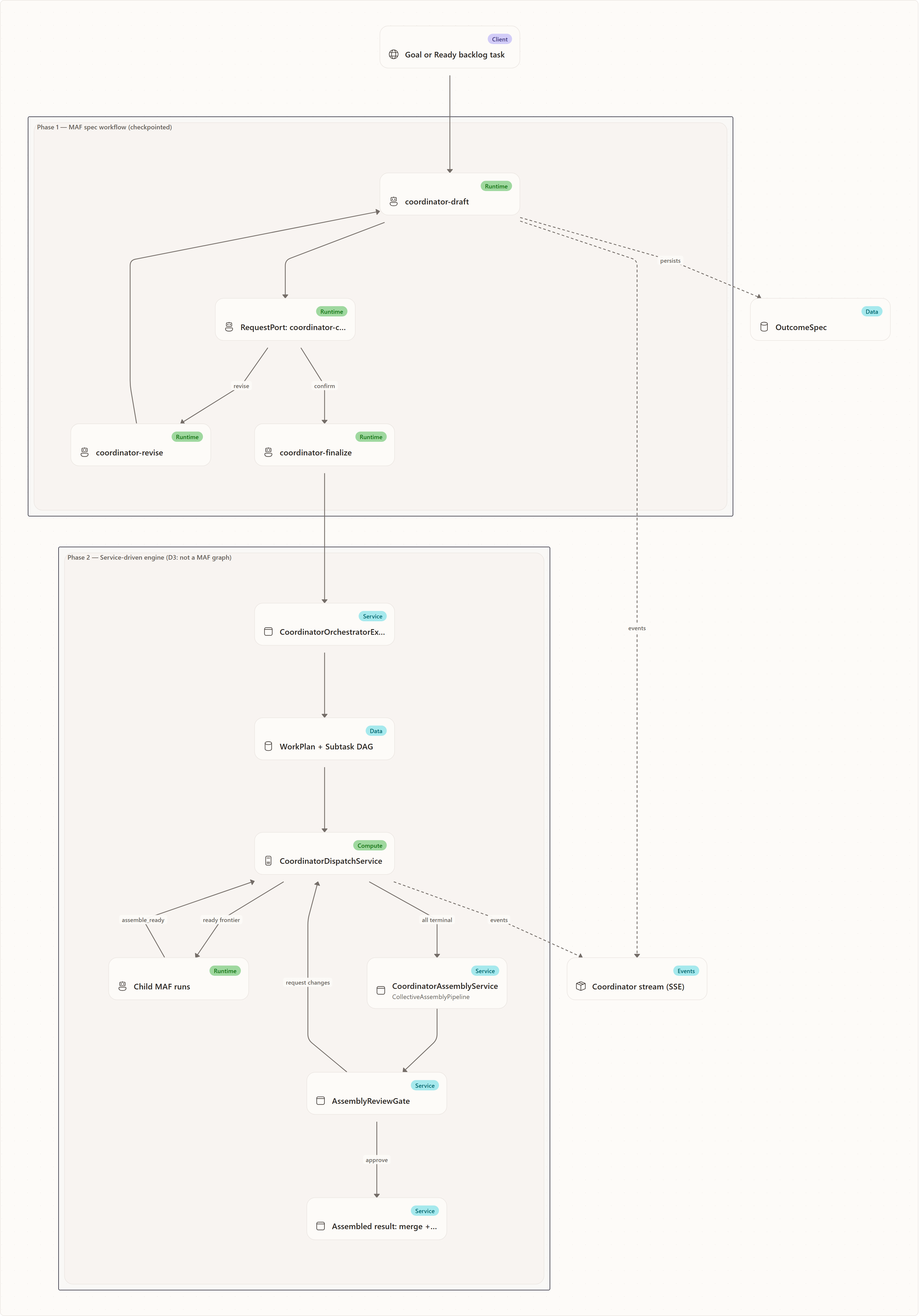
The durable artifacts are:
- Coordinator run — the parent run visible to clients.
- OutcomeSpec — the intent contract.
- WorkPlan — the execution contract for the confirmed outcome.
- Subtask rows and dependency edges — the dispatch DAG.
- Child runs — worker executions tagged with parent run id and subtask id.
- Coordinator stream events — the live and replayable explanation of what changed.
Core invariants
- Intent is confirmed before execution. The coordinator can draft and revise, but decomposition is authoritative only after confirmation or unattended confirmation.
- Plan before dispatch. Child runs are launched from a persisted WorkPlan, never from transient model text.
- One parent owns the combined outcome. Children do agent work; the parent owns the collective RAI pass, review, merge, and scribe.
- The dependency graph is the hard ordering rule. A subtask can run only when every dependency is satisfied.
assemble_readyandcompletedsatisfy dependencies.failed,rai_flagged, andblockeddo not; blocked dependents never become ready.- Isolation is advisory. Child subtasks share the orchestration worktree. File-scope declarations and conservative conflict checks reduce clobbering, but the coordinator may still reconcile overlapping edits during collective assembly using a child-wins strategy.
- Dispatch is single-writer. The dispatch loop owns subtask status mutation while active.
- Assembly is exactly-once by database compare-and-swap. In-memory guards are helpful but not authoritative.
- Recovery starts from persisted state. Restart logic routes by WorkPlan status, not by reconstructing chat history.
- Only terminally ineligible subtasks block assembly. Pending or still-running children are "not ready yet" and re-arm dispatch; only terminal non-eligible states such as failed/blocked/RAI-flagged produce an
assembly_blockedverdict (apps/Agentweaver.Api/Coordinator/AssemblyPlanning.cs:30,apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:563). - Stale assembly blocks can clear. If dispatch later observes every subtask eligible, it can advance
assembly_blocked -> awaiting_assemblyso a stale block does not latch forever (apps/Agentweaver.Api/Coordinator/CoordinatorDispatchService.cs:479). - Provider choice is not dynamic on the live path. The live coordinator path directly builds Copilot-backed agents; the Foundry dispatcher seam is plumbed but not active here.
Dispatchable-team guard layers
Coordinator orchestration no longer invents a default worker when a project has no cast team. The guard is layered so every entry point fails visibly instead of starting teamless work:
- Interactive start.
StartCoordinatorRunAsynccallsCoordinatorRosterGuard.EnsureDispatchableTeambefore the coordinator run row is inserted (apps/Agentweaver.Api/Coordinator/CoordinatorRunService.cs:111,:125). The project endpoint mapsNoTeamExceptionto409 no_teamandInvalidTeamExceptionto422 invalid_team(apps/Agentweaver.Api/Endpoints/ProjectEndpoints.cs:486). - Backlog pickup.
CoordinatorPickupServicechecks the same guard before activating a Ready backlog task. If the roster is absent or unreadable, it atomically reserves a failed coordinator run with resultno_teamorinvalid_teamand returns before any Core Implementer child work can start (apps/Agentweaver.Api/Coordinator/CoordinatorPickupService.cs:79,:106,:121). - Executor defense. The orchestrator resolves the roster from the same dispatchable-member predicate and fails the coordinator run with
no_teamif no candidate remains, rather than falling back to a fabricated worker (apps/Agentweaver.Api/Coordinator/CoordinatorOrchestratorExecutor.cs:140,:716). The predicate requires an active member with a role, then rejects Scribe, Ralph, RAI, and Build & Test names/roles (apps/Agentweaver.Api/Coordinator/CoordinatorRosterGuard.cs:54,apps/Agentweaver.Api/Coordinator/CoordinatorOrchestratorExecutor.cs:687,:750).
This preserves the coordinator's model: casting defines who can do work; orchestration only decomposes and assigns work to that real team.
Coordinator state machine
There are two overlapping state machines: the parent run status and the WorkPlan status. The WorkPlan is the more precise coordinator-internal state after planning.
RaiBlocked and NeedsResolution are parked or terminal states. Operators can recover some parked states through steering or full run retry, but the coordinator does not silently continue past them.
OutcomeSpec drafting logic
Why the OutcomeSpec exists
The OutcomeSpec prevents every worker from independently interpreting the user's broad request. It turns a goal into a stable contract:
- desired outcome;
- scope and exclusions;
- assumptions;
- material clarifying questions;
- current status: awaiting confirmation, confirmed, or declined.
This contract is stored before the work is decomposed. From that point forward, child workers should treat the spec and their subtask as source of truth rather than reinterpreting the original request.
How drafting works
The first coordinator phase is a Microsoft Agents Framework workflow:
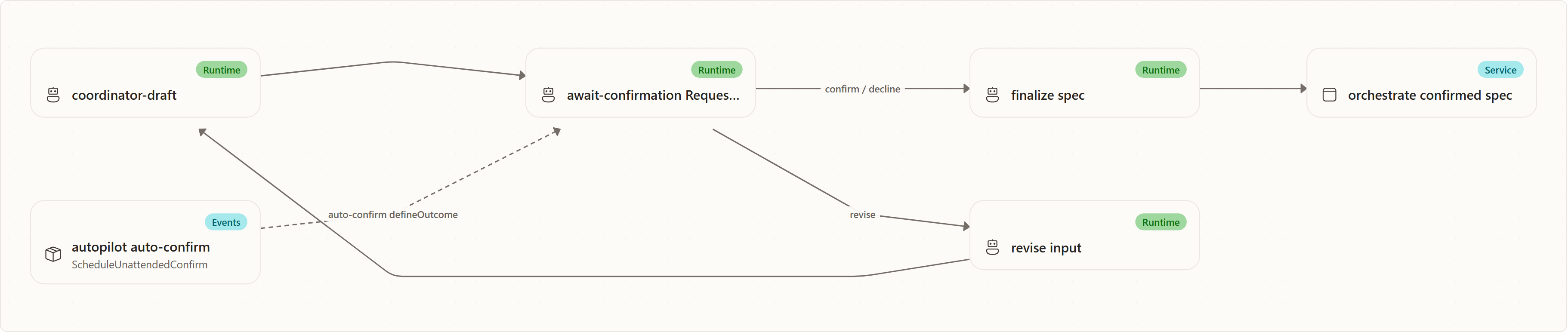
The drafting executor compiles team memory and active decisions, resolves the Coordinator charter, and runs a real Copilot coordinator turn. The prompt asks for one JSON object with desired_outcome, scope, assumptions, and clarifying_questions.
Two pieces of trusted, drafter-authored guidance are injected into that prompt so the confirmed outcome faithfully spans what the goal actually asks for — instead of collapsing a full-lifecycle request to a delivery-only MVP at the source:
- Team-capability awareness. Before drafting, the executor reads the project's
.squadroster and builds a terseTEAM CAPABILITIESlist — one line per dispatchable member as- {role-id} ({role title}). Platform infrastructure agents (Scribe, Ralph, RAI, Build & Test) are filtered out through the sameCoordinatorRosterGuard.IsDispatchableMemberpredicate the orchestrator and decomposer use, so the drafted outcome only promises deliverables some real worker role can produce. Roster resolution degrades gracefully: a missing, empty, or unreadable team simply omits the block rather than failing the draft (apps/Agentweaver.Api/Coordinator/CopilotCoordinatorSpecDrafter.cs:165,:190;apps/Agentweaver.Api/Coordinator/CoordinatorRosterGuard.cs:54). - Goal-breadth faithfulness. A
SCOPE BREADTHinstruction tells the model to enumerate every intermediate deliverable the goal explicitly asks for, not just the terminal artifact. When a goal asks for the full journey — "take this all the way from the initial idea through to a working, previewable app" — the drafteddesired_outcomeandscopeenumerate the discovery/PM/design/build deliverables the goal warrants (customer/market research, positioning/GTM/marketing, user stories, a PRD, and UX design in addition to the built app). When the goal is narrow (a bug fix, a small change, a single document), a symmetric lean guard keeps the outcome tight and forbids manufacturing lifecycle stages the goal never asked for. Genuinely ambiguous breadth becomes aclarifying_questionrather than an assumption of the widest scope (CopilotCoordinatorSpecDrafter.cs:205,:229).
The goal's stated breadth is the driver; the roster is only a capability filter. Breadth is read from the goal's own words, never inferred from team size or the presence of specialist roles, and the software-lifecycle stages above are illustrative examples — Agentweaver is a general orchestrator, so the drafter applies no hardcoded lifecycle checklist. Both the capability list and the breadth guidance are appended outside the <<<USER_GOAL>>> fences, so trusted roster/breadth text is never conflated with the untrusted goal and the prompt-injection defense is preserved (CopilotCoordinatorSpecDrafter.cs:210, :227).
Important details:
- The human goal and revision feedback are fenced as untrusted data. The model is instructed to restate intent, not obey prompt-injection text inside the goal.
- Drafting streams onto the coordinator run timeline so the UI does not show an empty run while planning happens.
- The parser tolerates extra prose by extracting the first JSON object, but required fields must exist.
- If the model is unavailable or the draft is unparseable, the coordinator run fails visibly. It does not fabricate a boilerplate spec.
- Revision overwrites the existing draft in place and re-arms it for confirmation.
Confirmation paths
Interactive defineOutcome runs suspend at the confirmation gate until a human confirms, revises, or declines — unless autopilot is on. When an interactive run starts with autopilot=true (POST /api/projects/{id}/orchestrations, defineOutcome mode), StartCoordinatorRunAsync schedules the same bounded ScheduleUnattendedConfirm loop and confirms the spec unattended once it reaches awaiting_confirmation, attributing the confirmation to the submitting user (confirmedBy = the authenticated caller). direct-mode runs have no confirmation gate, so no loop is scheduled for them.
Backlog pickup runs go through the same gate and the same unattended-confirm loop. When autopilot is on (PickupAutopilot: true, the project default), the loop fires once the spec reaches awaiting_confirmation and confirms it on behalf of the accountable human captured on the backlog item. When autopilot is off, no loop fires — the run stays at awaiting_confirmation until the human confirms via the UI. This is not Autopilot bypassing safety: the confirmation is still attributed to a named human (the submitting user for interactive runs, the captured accountable human for pickups), the gate is still enforced and recorded, and turning off autopilot simply makes that confirmation explicit instead of automatic. Autopilot also auto-answers child clarifying questions; it does not grant tool approvals or skip collective human review.
There is a small ordering race between "the spec was persisted and emitted" and "the framework request port is armed." The resume seam handles this by waiting briefly for the pending gate while the spec remains awaiting_confirmation, preserving double-submit protection without rejecting a fast confirm.
The web gate mirrors that race tolerance without hiding the safety state. OutcomeSpecPanel treats an early 404 from GET /api/runs/{id}/outcome-spec as "draft not persisted yet", keeps the panel visible in Drafting, and polls every two seconds until REST or SSE supplies the spec. If the run reaches a failure/decline terminal status before content exists, it shows a terminal drafting error (apps/web/src/components/OutcomeSpecPanel.tsx:160, :233, :328, :401, :537). The confirm button has both React state and a synchronous ref guard, disables confirm/revise while submitting, shows Confirming..., retries only 409 no_pending_gate, refreshes the snapshot on 409, and surfaces non-active conflicts instead of allowing duplicate confirmation attempts (OutcomeSpecPanel.tsx:237, :338, :345, :360, :578).
Workflow selection and WorkPlan decomposition
Workflow selection as shape guidance
After confirmation, the coordinator selects the workflow shape the work should follow. This is CoordinatorOrchestratorExecutor.SelectWorkflowAsync, and its defining property is deterministic-first: hard, cheap rules collapse the candidate space, and an LLM is consulted only when more than one workflow genuinely fits and no human has already named one.
WorkflowRegistry.ResolveDefault(project)resolves the project default first. It is both the selector's deterministic fallback (placed first in the candidate list) and the explicit valueSelectWorkflowAsyncreturns if any step throws.WorkflowRegistry.GetOrLoad(project).Availableis ordered default-first, then by id.ResolveInvocationKindAsyncmaps the run's origin to aWorkflowInvocationKind:RunOrigin.BacklogPickupbecomesHeartbeat; everything else (and any lookup failure) becomesManual.- A request-level dialog override (
CoordinatorDraftInput.WorkflowOverrideId, sourced fromStartOrchestrationRequest.workflow_override_id) is checked first. If absent, a backlog-task pin (BacklogTask.WorkflowOverrideId, viaResolveWorkflowOverrideIdAsync) is checked next. Either override short-circuits selection, but only when the workflow exists andWorkflowTriggerEvaluator.IsEligibleaccepts it for the invocation; otherwise the mismatch is logged and selection continues. WorkflowTriggerEvaluator.IsEligiblefilters the candidates by trigger. This is a hard boundary applied before any model call — a manual run never selects a heartbeat/event workflow and a heartbeat pickup never selects a manual-only one.- Zero eligible candidates → return the project default rather than a trigger-mismatched workflow.
- Exactly one eligible candidate → use it directly, with no model call and no selection event (the common, single-workflow project case stays silent and free).
- Two or more eligible candidates → build a
WorkflowSelectionContextand resolve the pick. An explicituse {workflow-id}in the revise feedback (WorkflowSelector.TryParseOverride) wins outright; otherwise the Copilot-backedWorkflowSelector.SelectAsyncchooses by process fit.
The LLM is therefore consulted in exactly one situation: 2+ trigger-eligible workflows and no explicit override. WorkflowSelector.SelectAsync itself is conservative — it short-circuits to the default when only one workflow is present, and any model failure, unparseable JSON, or unknown id (CopilotWorkflowSelectionModel returns null on failure) falls back to the first candidate, the project default. Failures are never silently swallowed: every multi-candidate resolution emits a coordinator.workflow_selected event (EmitWorkflowSelectedEvent) carrying the chosen id, a rationale, wasAutoSelected, an overrideHint, and the available set; and a thrown SelectWorkflowAsync logs a warning and returns the resolved default so the caller always knows what it is planning against.
The selected workflow is not just recorded for display. It becomes prompt context for decomposition so the resulting subtask graph mirrors the intended process shape. The run workflow factory resolves the effective workflow again at graph-build time, so a stale planning pick can never become unchecked execution.
Decomposition strategy
The decomposition turn asks for a subtask set that is outcome-complete — one that covers every lifecycle stage the outcome implies, rather than the fewest subtasks that technically compile. Every distinct deliverable or lifecycle stage the confirmed outcome calls for (customer/market research, business/GTM, user stories, PRD, UX design, implementation, and so on) must map to at least one independently dispatchable, well-scoped subtask owned by exactly one agent — a stage the outcome implies is never dropped, and two genuinely distinct deliverables are never merged. A symmetric anti-over-engineering guard balances that completeness: a small, well-defined change maps to a single implementation subtask, so trivial outcomes stay lean and no stage is manufactured that the outcome does not imply. This stays balanced only because the lifecycle breadth already originates upstream, in the confirmed outcome the drafter produces: decomposition inherits and honors that breadth rather than having to reconstruct it. Each subtask must include:
- title;
- exact scope, including files or outputs it owns;
- role id, preferably from the active roster;
- optional bespoke charter when no roster/catalog role fits;
- complexity;
- phase;
- advisory isolation hint;
- 1-based dependency indices.
The prompt drives the model toward bounded subtasks and explicit dependency edges, but the selected workflow is guidance for the stages it covers — not a cap on the plan. A functional workflow may model only part of the outcome; when the desired outcome implies earlier lifecycle stages the workflow's topology does not enumerate, the coordinator adds subtasks for them rather than truncating the plan to the workflow's shape. It also asks parallel file-producing subtasks to write unique outputs, then add a consolidation subtask when parallel research needs synthesis.
The decomposition turn is grounded in:
- the confirmed OutcomeSpec;
- the selected workflow summary;
- active roster roles;
- relevant architectural and scope decisions;
- coordinator memory/session context.
The same prompt-injection rule applies: spec fields are fenced and treated as data.
Defensive parsing and normalization
The WorkPlan builder assumes model output can be malformed and normalizes aggressively:
- extract the first JSON array;
- try a trailing-comma repair;
- skip invalid items rather than failing the whole array;
- require title and scope;
- rebase dependencies after skipped items;
- drop self-references and out-of-range dependencies;
- normalize complexity to low/medium/high;
- normalize phase to none/planning/execution/validation;
- default isolation to worktree;
- default role to core implementer;
- trim optional bespoke charters.
If no valid decomposition is available, the coordinator falls back to one deterministic execution subtask covering the whole confirmed outcome. This keeps the pipeline operational offline, unlike OutcomeSpec drafting where unparseable output fails visibly.
DAG repair
The dependency graph must be acyclic. If the model creates a cycle, the coordinator traverses dependencies in stable order and drops the back-edge that closes the cycle. It records a note in the plan's isolation summary rather than dispatching a deadlocked graph.
This is a pragmatic trade-off: it preserves progress for most accidental cycles while treating the removed edge as lower confidence than the rest of the ordering constraint. A stricter rebuild can fail and ask for clarification instead.
Assignment and model selection
Subtasks are assigned to active, dispatchable roster members. Built-in infrastructure agents such as Scribe and RAI are excluded. Role matching scores exact role/title matches, token overlap across capabilities and responsibilities, and phase affinity.
Model selection is fixed to GitHub Copilot on this path. A non-empty run model pin — the coordinator run's explicit modelId OR the project's GitHub Copilot default — wins for every subtask regardless of complexity:
- if the run carries a model pin (explicit request
modelId, else the project default), use it for every subtask; - otherwise use the assigned role's default model;
- otherwise use a catalog role default;
- otherwise use the configured Copilot default (
CoordinatorModelDefaults.DefaultCopilotModel = "claude-sonnet-4.6", overridable viaProviders:GitHubCopilot:Model; the stale hardcodedgpt-4olast-resort was removed in issue #238).
Because the pin wins uniformly, setting a project default (or passing an explicit modelId) disables per-role model differentiation for that run; leave the pin unset for mixed per-role models. The same precedence is honored when a reviewer rejection rotates a subtask to a different eligible author — the pin is preserved across the rotation rather than falling back to the rotated author's role default.
The persisted WorkPlan starts as planned, with subtasks in pending and dependency edges persisted by database ids.
Dispatch and child tracking
Ready frontier
Dispatch repeatedly computes the ready frontier:
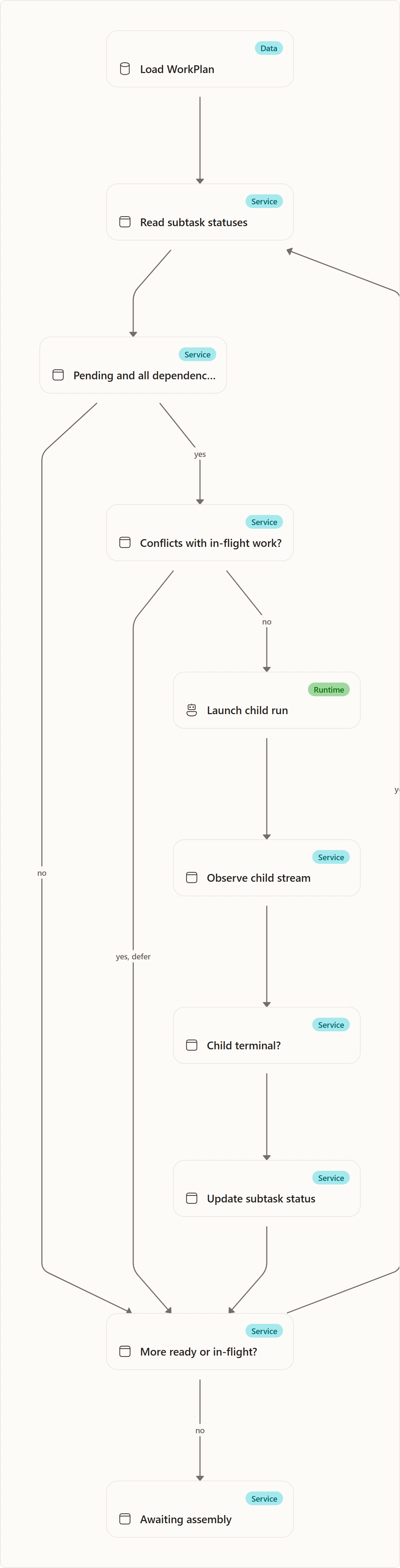
Only assemble_ready and completed satisfy dependencies. A failed or RAI-flagged dependency fails its still-pending dependents with recovery guidance, because serial dependents cannot safely proceed from a bad prerequisite.
Distributed pod lease on dispatching plans
Dispatching is a distributed single-writer section now, not just an in-memory one. The WorkPlan row carries CoordinatorPodId, which stores the pod/hostname currently holding the dispatch lease for that plan.
When a pod starts dispatch — or re-arms a previously orphaned dispatch loop — it first claims the lease by atomically updating the WorkPlan row (ExecuteUpdateAsync) to stamp CoordinatorPodId = <this pod> and refresh UpdatedAt. Only the replica whose conditional UPDATE actually affects the row proceeds to StartDispatch.
This was needed because the old reconciler relied on each process's local IsDispatchActive dictionary. In a multi-replica deployment, the Worker pod could have an active dispatch loop that API replicas could not see, so every replica sweeping "orphaned" dispatching plans could re-arm the same coordinator independently.
The reconciler now checks two things before trying to steal a plan:
- if another pod owns
CoordinatorPodIdand that claim is still fresh, it skips the plan; and - if the claim is missing or stale, it tries one conditional UPDATE to take ownership.
A lease is considered stale after Coordinator:PodLeaseStaleTtlSeconds (default 120 s, kept above the 90 s /healthz probe window so a probe pause never lets a peer steal a live lease).
Lease heartbeat
Stamping CoordinatorPodId at claim time is not enough on its own. The lease freshness signal is WorkPlan.UpdatedAt, and for a long time that column was only touched on status transitions. A dispatch loop that awaits a single child turn — an implement or debug run can take 5 to 15+ minutes — made no status change during that wait, so UpdatedAt aged past the stale TTL while the owner was perfectly healthy. A peer replica's reconciler then read the plan as an orphan, claimed it, and started a second dispatch loop. Both loops drove the same run and raced the shared /workspace/{projectId}/.git repo.
To close that gap, a pod that owns a dispatch loop runs an independent heartbeat (a PeriodicTimer on its own task) that renews the lease every Coordinator:PodLeaseHeartbeatSeconds (default 30 s, well under the 120 s TTL). Each tick runs from its own DI scope and DbContext — never the dispatch loop's context, which is not thread-safe — and issues an ownership-keyed conditional UPDATE: WHERE Id = @planId AND CoordinatorPodId = @myPodId AND Status = 'dispatching', setting UpdatedAt = now. A healthy owner therefore keeps the lease fresh for the whole child turn.
The heartbeat also fences the loop on lease loss. Loss is decided by ownership, not by the row count. When a renew affects zero rows, the heartbeat re-reads the plan:
- if
CoordinatorPodIdnow belongs to a different pod, the peer took over — the heartbeat cancels a per-runCancellationTokenSource(linked to app shutdown) so the fenced loop stops instead of continuing to race the repo, andStartDispatchlogs the stop as a fenced hand-off rather than a failure; and - if the row is still owned by this pod (the loop itself advanced
dispatching -> awaiting_assembly) or the row is gone, that is a benign stop — the heartbeat tears down without cancelling anything, so a normal hand-off never self-fences.
The heartbeat is stopped explicitly just before the awaiting_assembly hand-off and again in the loop's teardown, so it never outlives the loop it renews.
Assembly-phase lease heartbeat
The dispatch heartbeat only renews the lease while the plan is dispatching. The assembly phases (assembling / assembly_steering) have the same exposure: building the integration branch, the collective RAI / Rubberduck / Build & Test gates, and steering decisions routinely run well past the 120 s stale TTL with no status change, so UpdatedAt would age out and a peer reconciler could reclaim an actively-assembling run — re-running already-completed subtasks. The reconciler's IsAssemblyActive check is in-memory per pod, so it always reads false on a peer replica and cannot see the healthy owner's live loop.
CoordinatorAssemblyService therefore runs its own per-run heartbeat for the life of the assembly loop, launched alongside RunAssemblyAsync in StartAssembly and cancelled + awaited in the finally so it never outlives the loop (apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:288). Each tick (AssemblyHeartbeatTickAsync, :379) runs from its own DI scope + DbContext — never the assembly loop's context — and issues an ownership-and-status-keyed conditional UPDATE: WHERE Id = @planId AND CoordinatorPodId = @myPodId AND Status IN ('assembling','assembly_steering'), setting UpdatedAt = now. The interval reuses the same Coordinator:PodLeaseHeartbeatSeconds (default 30 s); no new config key is added.
The status set is exactly {assembling, assembly_steering}:
in_reviewis deliberately excluded so the heartbeat never masksCoordinatorReconciler.TryAbandonStaleReviewAsync's 24 h idle backstop (apps/Agentweaver.Api/Coordinator/CoordinatorReconciler.cs:396);in_reviewis already cross-pod-protected by the durable pending-gate check, not by the stale TTL.awaiting_assembly/assembly_blockedare excluded because their reclaim is not stale-TTL-gated.
Ownership decides the outcome, not the row count. When a renew affects zero rows the tick re-reads CoordinatorPodId: a peer owner (non-null and not this pod) returns PeerOwned and stops the heartbeat (this owner is being superseded); still-this-pod, a transient non-assembling status, or a missing row returns Idle — the tick is skipped but the loop keeps ticking, because the multi-phase lifecycle may re-enter assembling later (for example after a review approval). A transient per-tick DB/SMB blip is logged and the loop keeps heartbeating on the next interval — a single failed tick must never stop renewals (RunAssemblyLeaseHeartbeatAsync, :425).
Companion hardening (post-terminal delta drop). A late agent.message.delta arriving after a run is already terminal must never re-persist and re-drive the run or flood the stream past the heartbeat. Both event-stream backends drop only that one type once a run is completed — if (_completedRuns.ContainsKey(runId) && evt.Type == EventTypes.AgentMessageDelta) return; at the top of AppendAsync (apps/Agentweaver.Api/Infrastructure/SqliteRunEventStream.cs:86, apps/Agentweaver.Api/Infrastructure/EfRunEventStream.cs:70). Every terminal, diagnostic, final coalesced agent.message, tool, usage, subtask, and topology event still persists post-terminal for a durable audit trail and gapless replay.
Shared worktree conflict control
Child subtasks share one orchestration worktree. IsolationStrategy helps communicate intent, but it is not an enforced sandbox.
The dispatcher therefore adds two conservative safeguards:
- If multiple subtasks declare the same output file token, it serializes them by adding dependency edges.
- While a child is in flight, another ready subtask is deferred if their declared file tokens overlap. If either side declares no file tokens, they are assumed to conflict.
This favors correctness over maximum parallelism. A poorly scoped subtask may reduce parallelism, but it is less likely to clobber sibling work.
Dispatch lock contention on the dependency base branch
When dispatch rebuilds the dependency-base integration branch for downstream subtasks, it treats git ref-lock contention as a transient recovery case rather than a fatal orchestration fault. If LibGit2Sharp throws a locked-file error, the dispatcher asks WorktreeManager to best-effort delete stale .git/refs/heads/{branch}.lock and .git/packed-refs.lock files, then retries up to three times with a short linear backoff.
This path exists for crashed or interrupted prior processes that left a stale lock behind. If the retry still fails, dispatch logs the problem and continues without refreshing that dependency base branch, instead of crashing the whole coordinator loop.
Integration-branch build lock (per project)
The repo at /workspace/{projectId}/.git is shared by every run in a project (Azure Files SMB in the cloud), and WorktreeManager.BuildIntegrationBranch deletes and recreates the integration ref on each rebuild. Two builds racing that same repo produce a LockedFileException or a null ref while the ref is mid-swap — the second failure mode surfaced as an ArgumentNullException from Refs.UpdateTarget and pushed the run to assembly_blocked.
The lease heartbeat removes the usual cause of a second concurrent loop, but one residual window remains: BuildIntegrationBranch is a synchronous, non-cancellable LibGit2Sharp call, so a loop that has just been fenced cannot be drained out of the middle of a build. Two builds can also legitimately overlap across separate runs in the same project. To serialize them, both the dispatch dependency-base rebuild and the collective-assembly integration build take a per-project lock (repo granularity, not per-run) around the build.
The lock is a row in the IntegrationBuildLocks table, one per ProjectId, claimed with a conditional UPSERT (INSERT ... ON CONFLICT (ProjectId) DO UPDATE ... WHERE AcquiredAt < <stale threshold>) so exactly one caller wins. The same SQL runs on SQLite (local and tests) and Postgres (staging); a DB row is used rather than a named OS mutex (which would not span pods) or an SMB/git file lock (the substrate that fails under the race). Each acquisition mints a token that fences release, so a holder whose lock was reclaimed after the stale TTL can never delete the new holder's row, and a crashed holder's row is reclaimable after Coordinator:IntegrationBuildLockStaleTtlSeconds (default 300 s) rather than deadlocking the project. Acquisition waits up to Coordinator:IntegrationBuildLockAcquireTimeoutSeconds (default 120 s).
On the dispatch side the lock is best-effort: if a peer build holds it past the timeout, the rebuild is skipped, because the mandatory contains-check and repair before a dependent dispatches re-runs it. On the assembly side the final build proceeds even if the lock cannot be taken in time, since the existing retry-on-LockedFileException is the backstop and the final integration build must not be skipped. The pre-existing three-attempt stale-lock retry stays in place for locks left behind by a crashed process.
Child run construction
For each dispatched subtask, the coordinator creates a child run with:
ParentRunIdset to the coordinator run;SubtaskIdset to the subtask id;- assigned agent and selected model from the WorkPlan;
ModelSource = GitHubCopilot;- inherited run options such as auto-approve-tools and Autopilot;
- scoped approval inheritance for that project/run/subtask.
The child task includes the subtask title/scope, any recovery guidance, the parent OutcomeSpec, dependency summaries, and completed sibling outputs. That gives workers enough local context without asking them to rediscover the entire plan.
Child runs use the trimmed child workflow. They produce work and pass child-level safety checks, then stop at the assemble-ready boundary. They do not each perform human review, merge, or scribe. In production, the Worker executes those child agent turns in pod-per-run mode, so the live agent session runs inside a dedicated AgentHost pod rather than in-process on the Worker.
Observation and bubbling
The dispatch loop observes child runs through the durable run event stream. It replays the events already recorded for each child run and then tails new ones as they arrive, so the coordinator sees a complete, ordered history regardless of when it begins observing. This replay-then-tail model means observation is resumable: a coordinator that restarts can reconstruct child progress from the stream rather than depending on in-memory state.
Terminal child events map to coordinator outcomes:
run.assemble_readymaps toassemble_ready, unless safety was flagged;- content-safety failures map to
rai_flagged; - completed no-change runs map to
completed; - failed, declined, cancelled, and merge-failed child states map to
failed.
Mid-run child questions and tool approval requests are re-emitted on the coordinator stream with child run id, subtask id, and request id. Autopilot may answer bubbled questions by running a one-shot Copilot coordinator turn grounded in the OutcomeSpec and subtask. Tool approvals remain separate and are not auto-granted by Autopilot.
Observation includes stall handling. If a child emits no events within Coordinator:SubtaskStallTimeoutMinutes (default five minutes), the coordinator emits coordinator.child_stall_detected, persists any partial-output checkpoint it saw, and then — while recovery budget remains — redispatches the stalled subtask on a fresh child instead of failing it, incrementing the recovery-attempt counter; only once the budget is exhausted does the stall become terminal (see Stall redispatch before dead-end below).
An unresolved tool-approval gate is exempt from that stall timer (issue #212). While a child's most recent interaction is a tool.approval_required that has not resolved — with only tool.approval_pending heartbeats (every ~20s) following — the watcher records the pending requestId and treats the child as a legitimate human-paced wait, logging and continuing to observe instead of firing agent_stall_timeout. The exemption self-heals and cannot latch: any other real event (tool.result on grant, tool.error on deny/expiry, tool.approval_resolved, agent output, or a terminal event) clears the flag, so a pod that genuinely hangs after a gate self-expires is still caught. The guard also protects gate sites that emit no heartbeat, such as the preview gate (AgentPreviewGate.RequestApprovalAsync). See the Tool Approval SSE Contract.
A child whose AgentHost sandbox pod is still being provisioned is exempt from the same stall timer (issue #217). Kubernetes owns pod admission and scheduling, so a SandboxClaim can sit unbound (pod Pending) while a node frees up or katapool autoscales — a legitimate wait, not a stall. While the claim is unbound the executor emits a sandbox.provisioning_pending heartbeat (about every 20s) on the child stream; the watcher records that the child's most recent event is that heartbeat and, on stall-TTL expiry, resets the window and keeps observing instead of firing agent_stall_timeout. Like the approval-gate guard it self-heals and cannot latch: any other real event (the pod binding, agent output, or a terminal event) clears the flag, so a pod that genuinely hangs after provisioning is still caught. This mirrors the #212 tool.approval_pending mechanism.
Pending dependents of that stalled prerequisite do not become runnable. Instead, the dispatcher marks them blocked: a terminal, assembly-ineligible status that does not satisfy dependencies and means "this subtask never ran because an upstream dependency stalled." That distinction matters operationally: the stalled child owns the failure, while the blocked dependents record the cascade.
Stall redispatch before dead-end
A single stalled subtask used to dead-end the entire run: the frontier (SubtaskFrontier.ReadyPending) only dispatches pending subtasks, so a subtask terminalized as failed never re-entered, and the eligibility gate then stopped assembly with coordinator.assembly_blocked: ineligible_subtasks → coordinator.assembly_failed. Marking the stall terminal wasted a run that may have completed every other subtask.
The dispatch loop now spends the subtask's bounded recovery budget before dead-ending. In the ChildOutcome.Stalled branch, TryRedispatchStalledSubtaskAsync runs first (apps/Agentweaver.Api/Coordinator/CoordinatorDispatchService.cs:399, :1235):
- If
RecoveryAttempts < CoordinatorSteeringService.MaxRecoveryAttempts(3), the subtask row is revived for a fresh child —Status = pending,ChildRunId = null,PriorChildRunId = childRunId(so the fresh child builds on the prior branch through the existing handoff bundle),RecoveryAttemptsincremented monotonically (never reset),UpdatedAt = now— persisted from a fresh DI scope +DbContext(mirroringApplyStallFailureAsync). The in-memorystatusByIdentry is set back topending, acoordinator.subtask_redispatcheddiagnostic is emitted, and the loopcontinues soSubtaskFrontier.ReadyPendingredispatches it next iteration on a fresh pod. The old child run is still terminalized (agent_stall_timeout) and its AgentHost pod released — only the subtask is reset. - Once the budget is exhausted (
RecoveryAttempts >= MaxRecoveryAttempts), the loop falls through to the pre-existing dead-end path:ApplyStallFailureAsyncterminalizes the subtaskfailed,PropagateBlockedDependentsAsyncmarks its dependentsblocked, and assembly stops at the eligibility gate. This is now a genuine terminal after up to three bounded attempts, not on the first stall.
Because RecoveryAttempts is capped and never reset, the redispatch cannot loop forever, and single-replica runs simply gain up to three fresh attempts before reaching the same terminal they had before. The coordinator.subtask_redispatched payload (subtaskId, priorChildRunId, attempt, maxAttempts, reason) is documented in the events reference.
Topology emission and pod registry projection
Each phase transition and subtask state change emits a coordinator.topology event on the coordinator stream. The event is either a snapshot (full node list + edges, seq: 0) or a delta (seq > 0, changed nodes only). Edges are emitted only in the snapshot and never change after the work plan is confirmed.
CoordinatorTopology.BuildSnapshot and CoordinatorTopology.SubtaskNode are the two emission helpers (apps/Agentweaver.Api/Coordinator/CoordinatorTopology.cs). Both accept an IPodNameRegistry? to populate executionPodName per subtask node:
- Subtask node —
executionPodNameis set to the Kubernetes pod name registered under the subtask'schildRunIdinIPodNameRegistry.nullwhen the subtask has not been dispatched yet or the pod binding has not been recorded. - Coordinator node —
executionPodNameis set to the Kubernetes pod name of the API process itself (passed ascoordinatorPodName, sourced fromIKubernetesEnvironment.PodName).nullwhen running outside Kubernetes.
The frontend renders a pod chip on a node only when executionPodName is non-null. It does not fall back to the API pod name for child or intermediate nodes. This means a subtask that has not yet been bound to a pod shows no chip — which is accurate, not misleading.
IKubernetesEnvironment.PodName returns Environment.MachineName inside a Kubernetes cluster (the pod hostname equals the pod name in a default deployment) and null otherwise (apps/Agentweaver.Api/Infrastructure/KubernetesEnvironment.cs).
Collective assembly
When all subtasks settle, dispatch moves the WorkPlan to awaiting_assembly and hands off to the assembly service. Assembly is service-driven rather than a MAF workflow because it starts from already-produced git state, has a coordinator-owned review gate, and routes review changes back to re-dispatch rather than back to one model turn.

Exactly-once claim
Assembly starts with a database compare-and-swap from awaiting_assembly to assembling, stamping the integration branch. Only the winner proceeds. This is the authoritative exactly-once guard across dispatch completion, recovery, and review-triggered re-dispatch.
Authored assembly gates
After the integration branch is built, the coordinator resolves assembly gates from the selected workflow's happy path rather than from YAML node declaration order. It breadth-first traverses from start, following unconditional edges plus approved, pass, and review verdict edges, then runs matching gates in that traversal order (apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:1121, :1164, :1190).
Known assembly gates are rai, rubberduck, build-test, and human-review; build_test workflow nodes normalize to build-test (CoordinatorAssemblyService.cs:1128). The built-in software workflows now put RAI before Build & Test on the approval path: bug fix runs RAI -> Build & Test -> Human Review, while software delivery runs RAI -> Rubberduck -> Code Review -> Build & Test -> Human Review.
Build & Test is a platform gate, not a human action. The assembly service emits coordinator.assembly_review_requested with gateKind: "build-test", creates a detached worktree from the integration branch, runs the build/test verdict turn, and routes its verdict before the human-review gate (CoordinatorAssemblyService.cs:671, apps/Agentweaver.Api/Git/WorktreeManager.cs:155). In pod-per-run mode, the pipeline launches a dedicated AgentHost pod bound to the coordinator run id and passes the detached worktree path as the working-directory override (apps/Agentweaver.Api/Coordinator/CollectiveAssemblyPipeline.cs:155, apps/Agentweaver.Api/Sandbox/IAgentHostPodLifecycle.cs:30). /configure then sets the AgentHost working directory/file-tool root to that path before the first turn (apps/Agentweaver.Api/Sandbox/KubernetesSandboxExecutor.cs:300, :423). This gives the automated gate a routable A2A endpoint and a stable pod for the later deterministic preview step. Because that detached worktree uses the git CLI (WorktreeManager.cs:546), the API runtime image installs git alongside libgit2 (apps/Agentweaver.Api/Dockerfile:58).
Preview is decoupled from the Build & Test model verdict. After RunBuildTestAsync returns, PreviewStep.RunAsync runs for approved or request-changes verdicts and skips only declined verdicts (CoordinatorAssemblyService.cs:753). It is deterministic and platform-owned: PreviewCommandResolver finds a command, the API calls AgentHost /preview-runner/*, AgentHost observes the actual bound port, and the API registers the Gateway preview with that observed port (apps/Agentweaver.Api/Coordinator/Preview/PreviewStep.cs:70, apps/Agentweaver.Api/Sandbox/Preview/PreviewCommandResolver.cs:25, apps/Agentweaver.Api/Sandbox/Preview/PreviewRunnerHttpClient.cs:78).
Preview failure is deliberately non-blocking. PreviewStep emits sandbox.preview_ready, sandbox.preview_failed, or sandbox.preview_skipped_not_applicable as the terminal preview outcome, and any failure still lets human review proceed (PreviewStep.cs:229, :258, :272). The old approval-time guard remains a safety net: if no final outcome exists, it emits sandbox.preview_failed with reason: "preview_outcome_missing" rather than resetting and redispatching subtasks (CoordinatorAssemblyService.cs:2455). See Decoupled live-preview provisioning.
Automated gate request-changes now route through unified steering rather than a hidden reset-and-redispatch reflex. RouteAssemblyGateThroughSteeringAsync emits coordinator.steering_received, invokes the coordinator decider inline, and emits coordinator.steering_decision before executing the chosen action (apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:1680). A decision can steer in place, dispatch fresh, proceed/terminal, or record an advisory no-op. Fresh dispatch is the only path that resets subtasks, and it is visible before the reset. In-place revision failures now terminalize visibly (run.failed reason child_executor_failed:{executor} plus failed workflow.step) and then fall back through a conscious dispatch_fresh decision when needed, so assembly does not silently wedge. See Unified autonomous steering.
Eligibility gate
The coordinator does no partial assembly. Every subtask must be assemble_ready or completed.
assemble_readymeans the child produced changes to assemble.completedmeans the child completed with no mergeable changes; this is an eligible no-op.failed,rai_flagged, and still-running statuses block the whole plan.
Integration branch
Eligible child branches are merged into one integration branch in dependency order. Completed no-op children are eligible but contribute no branch. If a merge conflict appears while adding one child branch, the coordinator currently auto-resolves it by accepting that child's version for every conflicting path, emits coordinator.integration_conflict_auto_resolved, and continues with the remaining children. This means an agent modifying a file outside its primary output scope is acceptable: the parent coordinator reconciles the overlap with a child-wins strategy rather than blocking assembly. A future follow-up should distinguish this safe case from true sibling-vs-sibling conflicts and surface those as needs_resolution.
Collective RAI
The production pipeline reuses the existing RAI executor over the aggregate diff. When the integration has changes, the coordinator first provisions one detached reviewer worktree checked out at the integration tip and passes its path to both the collective RAI and Rubberduck reviewers, so they review the actual assembled files — raw bytes, line endings, integration state — rather than only the aggregate diff string. This eliminated spurious blocking findings and premature human escalation that arose when reviewers received only the diff text with an empty worktree path. The reviewer worktree reuses the deterministic Build/Test worktree name, so Build & Test destructively recreates the same worktree when it runs (no reviewer-write bleed into Build/Test) and the existing Build/Test cleanup path tears it down with no extra wiring; empty-diff assemblies skip the worktree entirely (apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyService.cs:785, apps/Agentweaver.Api/Coordinator/CollectiveAssemblyPipeline.cs:298). A collective RAI safety flag is a hard stop: the WorkPlan is marked rai_blocked, the coordinator run is failed, and a human override/recovery path is required.
Build & Test infrastructure classification
Build/test code feedback and sandbox infrastructure failures take different paths. A request-changes decision from the Build & Test agent is authored feedback and uses normal redispatch routing. Infrastructure failures are classified before that verdict layer: launch failure, missing pod IP, missing A2A endpoint, and A2A transport errors become build_test_infra_* reasons (CollectiveAssemblyPipeline.cs:174, :252; KubernetesPodAgentEndpointResolver.cs:103, :177; RemoteAgentProxy.cs:119, :243). Retryable cases park the plan as assembly_blocked so the reconciler can re-arm it; non-retryable configuration errors mark assembly_failed and terminalize the coordinator (CoordinatorAssemblyService.cs:1567, CoordinatorReconciler.cs:267). The emitted diagnostic payloads carry detail, exceptionMessage, innerExceptionMessage, innerExceptionType, and infrastructureReason, so operators can see the actual AgentHost launch or transport root cause rather than only build_test_infra_agenthost_launch_failed (CoordinatorAssemblyService.cs:1590, :1604, :1648). These events are persisted even when they are appended around terminalization because the run event stream writes late appends before checking completed-run state (SqliteRunEventStream.cs:81, EfRunEventStream.cs:64). They no longer masquerade as REQUEST_CHANGES, so they do not create a redispatch loop that keeps asking workers to fix unavailable infrastructure.
One collective review
The human reviews the combined integration result once. The gate is an in-memory, owner-scoped task keyed by coordinator run id. It is at-most-once: double submissions find no armed gate after the decision is consumed.
Review decisions:
- Approve — proceed to one collective merge.
- Request changes — submit unified steering feedback to the coordinator. The coordinator chooses in-place steering, fresh dispatch, proceed/terminal, or advisory no-op.
- Decline — mark assembly declined and terminalize the coordinator run.
- Timeout/cancel — leave recoverable or mark failed depending on path.
Request-changes routing
The assembly Build & Test pod, detached worktree, and any Gateway preview are intentionally retained while the run waits at human review, so reviewers can open the preview URL against the exact assembled tree. They are also retained across automated Build & Test / Rubberduck request-changes redispatches, which preserves context and avoids a second-pass AgentHost relaunch failure class. Cleanup still runs on terminal outcomes, and it still runs before non-automated request-changes redispatches where the old review context should be discarded (CoordinatorAssemblyService.cs:1536, :1548, :1869, :1918). AgentHostReaperService treats AwaitingReview as active, so review/preview AgentHost claims are not reaped during that window (apps/Agentweaver.Api/Sandbox/AgentHostReaperService.cs:86, :102).
When a gate requests changes, the coordinator avoids redoing everything by scoping to the reviewer's implicated subtasks (#223):
- Read the reviewer's structured
TARGET_FILES:hint (ReviewTargetFiles.Parse) — a machine-readable directive line, not prose scraped from feedback. - Reverse-map those files onto the assembly-eligible subtasks that actually committed them (
AssemblyPlanning.ScopeImplicatedSubtasks) — the implicated set. Only these authors are eligible for author lockout. - Sweep the implicated set's transitive dependents (
AssemblyPlanning.TransitiveDependents) — they must rebuild against the revised contract, but their authors are never locked out (locking a blameless dependent re-creates the roster-exhaustion deadlock). - If the hint is missing or reverse-maps to nothing, fall back to all contributors (fail-safe) and emit
coordinator.assembly_implicated_scope_fallback.
The implicated subtasks are reset to pending with recovery guidance containing the review feedback; their already-satisfied dependents are reset too (RedispatchDependentsAsync). Other completed subtasks remain intact. The WorkPlan returns to dispatching, and the dispatch loop re-runs the affected frontier. After those children finish, assembly starts again from awaiting_assembly.
Merge, scribe, and decision promotion
Approval triggers one merge of the integration branch into the originating branch, serialized by the repository merge lock. Merge conflicts become needs-resolution. Non-conflict merge failures become assembly failures.
After a successful merge, the coordinator runs one collective Scribe pass. Scribe is best-effort: failure is visible but does not fail the already-merged assembly. The coordinator then promotes pending architectural and scope decisions created by the coordinator during the run, marks the WorkPlan complete, terminalizes the parent run, persists stream events, and completes the stream.
Recovery and retry semantics
The coordinator assumes in-memory drivers can disappear. Recovery routes by durable WorkPlan state.
| Durable state | Recovery action |
|---|---|
| No WorkPlan | Resume the checkpointed spec draft/confirmation workflow. |
| WorkPlan with no subtasks | Finalize the coordinator run from the spec status. |
planned or dispatching | Reset in-flight subtasks to pending and re-arm dispatch. |
awaiting_assembly | Re-arm assembly; the CAS decides the winner. |
assembling or in_review | Reset to awaiting_assembly and re-run assembly to recreate the assembly driver and review gate. Deferred review decisions submitted to a non-owner replica are durable and are consumed by the owner driver after the gate is re-armed. |
complete | Settle the coordinator run as completed if it was still in progress. |
| blocked/failed/declined assembly states | Settle the coordinator run as failed or declined with the recorded reason. |
The heartbeat also runs a reconciler. It scans for orphaned dispatching, awaiting-assembly, and assembling plans whose in-memory loop is gone, recreates the coordinator stream if needed, and re-arms the correct service. For dispatching plans it honors the distributed CoordinatorPodId lease first, skipping freshly owned plans and stealing only stale ones. Each candidate is isolated by try/catch so one corrupt plan does not stop the sweep.
Bounded final-Scribe recovery
At startup, recovery checks terminal coordinator runs for a missing final Scribe. It skips runs that already have a Completed or InProgress Scribe child, and stops retrying after the configured number of Failed attempts. Per-run admission prevents duplicate local launches, while a SemaphoreSlim bounds concurrent in-process Scribe pipelines.
| Configuration key | Default | Effect |
|---|---|---|
Coordinator:FinalScribeMaxConcurrency | 2 | Maximum final-Scribe recovery pipelines admitted concurrently in this process; values below 1 are floored to 1. |
Coordinator:FinalScribeMaxAttempts | 3 | Maximum Failed final-Scribe child attempts before recovery stops admitting another attempt; values below 1 are floored to 1. |
Coordinator:FinalScribeTimeoutSeconds | 120 | Maximum time the terminal assembly path retains the per-run AgentHost pod for the final Scribe turn before recording a non-fatal timeout and releasing run resources; values below 0.1 are floored to 0.1. |
Reaper as the 3rd heartbeat phase
CoordinatorHeartbeatService drives three phases per tick:
- Backlog pickup — claim Ready tasks and start coordinator runs.
- Work-plan reconciliation — re-arm orphaned dispatching/assembly plans.
- Agent-host pod reaper — invoke
AgentHostReaperServiceto sweep and terminate orphaned agent-host pods.
The reaper phase runs every Coordinator:ReaperIntervalTicks ticks (default 12, i.e. roughly every 2 minutes at the default interval). This is intentionally coarser than the heartbeat cadence; the reaper lists all pods in the namespace each sweep, so running it on every tick would be excessive.
The reaper is the last line of defense against quota leakage. The normal dispatch paths call ReleaseAgentHostPodAsync on all stall-fail and cancellation paths first; the reaper terminates any pod that slips through.
Automation name in tick records
Each heartbeat tick carries an automation name string that identifies which background automation produced the record. HeartbeatStatusStore.TickRecord and RecordTickOutcome include an AutomationName property (e.g. "Coordinator Heartbeat", "Checkpoint GC"). The HeartbeatStatusDto.TickRecordDto exposes this as the automation_name field in the API response.
The frontend Heartbeat page shows Automation as the first column in the Recent Activity table, so operators can distinguish which automation ran on each tick at a glance.
{
"tick_records": [
{
"automation_name": "Coordinator Heartbeat",
"acted_count": 2,
"error_count": 0,
"duration_ms": 340,
"recorded_at": "2026-06-27T18:00:00Z"
},
{
"automation_name": "Checkpoint GC",
"acted_count": 0,
"error_count": 0,
"duration_ms": 12,
"recorded_at": "2026-06-27T17:59:50Z"
}
]
}Failure containment
Several paths intentionally convert ambiguous failure into durable, inspectable state:
- Child start failure creates a terminal failed child run before marking the subtask failed, so embedded child-run inspection has a durable record to render.
- Orphaned/stalled children are failed after the stall TTL instead of being observed forever, and the coordinator emits
coordinator.child_stall_detected. - Pending dependents of a failed prerequisite are failed with recovery guidance; pending dependents of a stalled prerequisite are marked
blocked. - Unexpected assembly exceptions mark the WorkPlan failed, emit a human-readable assembly failure, terminalize the run, and complete/persist the stream.
- Corrupt reconciler candidates are marked failed rather than retried endlessly.
- Steering recovery is capped per subtask to avoid infinite auto-resume loops.
Steering and operator recovery
Steering is the live control surface:
- send records an informational nudge and changes no state.
- stop cancels active child workflows and can terminalize the coordinator on broadcast stop.
- redirect and amend queue instructions for a child's next turn boundary.
- A targeted redirect can force-complete a stuck child stream so the dispatch loop reaches a boundary and applies the directive.
- For parked coordinators, redirect/amend can reset affected subtasks to pending, reopen the coordinator stream, un-terminalize the run when appropriate, and re-arm dispatch.
The semantics are deliberately "honest": there is no mid-token or mid-tool magical pause. Direction changes apply at turn boundaries or through explicit cancellation/re-dispatch.
Retrying a pickup run
Retrying a failed backlog-pickup coordinator creates a fresh parent run with RetriedFrom pointing to the source run and preserves the durable backlog-pickup origin and accountable human. It does not silently re-claim or duplicate the backlog task.
CopilotAIAgent vs AgentRunnerDispatcher
The live coordinator path is Copilot-backed in multiple places:
- outcome-spec drafting constructs
CopilotAIAgentdirectly; - workflow selection constructs
CopilotAIAgentdirectly; - decomposition constructs
CopilotAIAgentdirectly; - Autopilot question answering constructs
CopilotAIAgentdirectly; - child runs are created with
ModelSource.GitHubCopilot; - live workflow execution uses the Copilot workflow turn-agent path.
The provider-neutral AgentRunnerDispatcher can route one-shot runner calls to Foundry, but that seam is not active for the live coordinator/run workflow path. Rebuilding provider choice for coordinator execution requires adding an explicit workflow turn-agent selection point and preserving setup, event normalization, tool governance, checkpointing, and child-run semantics for the new provider.
Common failure modes
| Failure mode | Coordinator behavior |
|---|---|
| Draft model unavailable or unparseable | Fail visibly; do not invent an OutcomeSpec. |
| Decomposition model unavailable or malformed | Fall back to one deterministic subtask. |
| Model creates dependency cycle | Drop cycle-closing edges deterministically and note it. |
| Workflow selection fails | Fall back to project default workflow. |
| Child run cannot start | Persist terminal failed child run, then fail the subtask. |
| Child safety flagged | Mark subtask rai_flagged; dependents do not proceed. |
| Child stream stalls | Emit coordinator.child_stall_detected, persist partial output checkpoint when possible, fail the stalled subtask, and mark pending dependents blocked. |
| Assembly has ineligible subtasks | Block whole assembly; no partial merge. |
| Integration branch conflict | Mark needs resolution; do not enter review/merge. |
| Collective RAI flagged | Current behavior: mark rai_blocked and terminalize failed. |
| Build & Test infrastructure failure | Classify as build_test_infra_*; retryable cases park as assembly_blocked, non-retryable configuration errors fail assembly. |
| Review requests changes | Reset inferred subtasks and dependents, then re-dispatch. Automated Build & Test / Rubberduck request-changes retain the assembly Build & Test pod and detached worktree for reuse; non-automated request-changes clean those resources up first. |
| Review declines | Mark assembly declined and terminalize. |
| Merge conflict | Mark needs resolution / merge failed. |
| Scribe fails after merge | Emit failure event but keep assembly successful. |
| Process restarts mid-run | Route by persisted WorkPlan status and re-arm idempotent engines. |
Trade-offs
Why mix MAF workflow and service-driven loops?
The confirmation phase benefits from MAF request ports and checkpoints because it is a human-suspendable model workflow. Dispatch and assembly are better as durable service loops because they supervise many child runs, rebuild in-memory gates, and advance from relational state.
Why fail hard for spec drafting but not decomposition?
An invalid OutcomeSpec means the system has not established intent. Fabricating one would violate the confirmation contract. An invalid decomposition happens after intent is confirmed; a one-subtask fallback preserves correctness, though with less parallelism.
Why no partial assembly?
Partial assembly risks shipping an inconsistent subset of a team plan. The coordinator instead requires every subtask to be eligible, then assembles the whole result once.
Why conservative file conflict rules?
All child runs share a worktree. If the coordinator cannot prove two subtasks own disjoint files, it serializes them. This may reduce parallelism but avoids silent clobbering.
Why reset assembly after restart from in_review?
The review gate is in memory. After restart, the HTTP endpoint has nothing to complete. Resetting to awaiting_assembly rebuilds the integration branch, re-runs the needed stages, and re-arms the review gate from durable state.
Rebuild blueprint
To rebuild the coordinator from scratch:
- Define durable state first. Create parent runs, OutcomeSpecs, WorkPlans, Subtasks, dependency edges, steering directives, and run events.
- Implement draft/revise/confirm. Use a checkpointed workflow or equivalent request-port mechanism; persist the spec before asking for confirmation.
- Fence untrusted user text. Treat goals, spec fields, feedback, and child questions as data inside prompts.
- Select workflow shape conservatively. Filter by trigger, honor safe overrides, and default deterministically.
- Decompose into a minimal DAG. Parse defensively, normalize fields, repair or reject cycles, and persist before dispatch.
- Assign real workers. Exclude infrastructure agents, choose roster members by role fit, and make model/provider selection explicit.
- Dispatch only the ready frontier. Use satisfied dependencies and conflict checks to control parallelism.
- Treat child runs as fragments. They should stop at assemble-ready; parent-level review/merge/scribe happens once.
- Observe by durable events. Replay then tail where possible; map child terminals into subtask statuses.
- Bubble human gates. Re-emit child questions and approvals on the parent stream with enough correlation to answer the child.
- Assemble exactly once. Use a database CAS for the
awaiting_assembly → assemblingclaim. - Require all children to be eligible. Build one integration branch in dependency order and review the aggregate.
- Route review feedback to affected subtasks. Infer files, include dependents, reset selected subtasks with recovery guidance, and re-dispatch.
- Make every failure durable and explainable. Terminalize parent and child rows with reasons; persist stream events before completing.
- Recover by state, not memory. On startup and heartbeat, route by WorkPlan status and re-arm idempotent drivers.
- Do not assume dispatcher provider support reaches live workflows. Add provider selection at the workflow turn-agent seam if live coordinator runs need non-Copilot providers.
v0.9.5 observable run-page projection
The current coordinator UI projection is intentionally seeded from durable artifacts, not only from a live SSE stream. CoordinatorRunPage fetches the work plan and children together, stores workPlanData, and calls seedTopologyFromWorkPlan(workPlan, children) so a completed or reloaded run renders the planned graph immediately (apps/web/src/pages/CoordinatorRunPage.tsx:1974, :1987). It then inserts synthetic Outcome plan and Work plan nodes into the graph before the downstream subtask nodes, making the planning contract visible as part of the executable topology (CoordinatorRunPage.tsx:2224, :2272).
The docked session model mirrors the full plan. Every planned subtask is included in the session tree even if no child run exists yet; child-run transcripts and artifacts appear once childRunId is present (CoordinatorRunPage.tsx:2702; apps/web/src/components/AgentSessionPanel.tsx:1640). The tree is flat under the coordinator root by design: dependency ordering is represented by graph edges, not by tree nesting (CoordinatorRunPage.tsx:2802).
AgentSessionPanel converts raw event streams into a readable coordinator narrative. It builds subtask metadata from coordinator.work_plan and subtask.* payloads, then formats dispatch/running/ready/completed/failed lines with title, agent, role, and reason (apps/web/src/components/AgentSessionPanel.tsx:1314, :1360). The panel classifies technical scaffolding separately from high-signal content, and docked coordinator panels expose a technical-details toggle instead of mixing raw tool/file rows into the primary narrative (AgentSessionPanel.tsx:740, :2160).
Durable assembly review gate
The review gate is persisted outside the in-memory assembly driver. CoordinatorAssemblyReviewPersistence.UpsertReviewRequestAsync records the owner, integration branch, and aggregate tree hash for the coordinator run; PersistDecisionForPendingRequestAsync accepts a decision only when the associated WorkPlan is still in_review and at the review assembly stage (apps/Agentweaver.Api/Coordinator/CoordinatorAssemblyReviewPersistence.cs:11, :111, :196). This prevents the coordinator from completing as though the collective review had closed when the human decision has not been durably recorded.
When the coordinator fails while the review is open, MarkCoordinatorFailedAsync stamps CoordinatorFailedAt and CoordinatorFailureReason and returns true so the open review can remain visible instead of being cleared as decided (CoordinatorAssemblyReviewPersistence.cs:167). The WorkPlan adds AssemblyTerminalStage and AssemblyStatusReason, keeping the failing gate/action separate from later cleanup stage movement (apps/Agentweaver.Api.Data/Memory/WorkPlan.cs:34).
Where this lives
apps/Agentweaver.Api/Coordinator/apps/Agentweaver.Api/Runs/apps/Agentweaver.Api/Memory/packages/Agentweaver.AgentRuntime/Workflow/packages/Agentweaver.AgentRuntime/CopilotAIAgent.cs
See also
- Resilient assembly-review loop — Deep Dive — the hardening built on top of the assembly pipeline: budget-exhausted escalation, accumulated context, reviewer-rejection lockout, and reliable child-turn terminal emission.
- Events reference —
coordinator.subtask_redispatched— the diagnostic emitted when a stalled subtask is redispatched before dead-ending. - Git integration — resilient worktree deletion — how assembly Build & Test survives the Azure Files SMB
Directory not emptywindow during worktree teardown.