
Agent Runtime & Tools — Conceptual Deep Dive
Purpose and scope
The runtime turns a human request into an agent turn, makes tools available safely, selects providers, and records what happened. The goal is to explain the logic well enough for an engineer to rebuild the runtime from first principles, not to trace source files line by line.
Primary scope:
Agentweaver.AgentRuntime: the turn loop, provider seams, workflow agents, governance, RAI/Scribe touchpoints, and event emission.Agentweaver.AgentTools: the model-callable tool catalog and the per-run context that makes tools safe and reproducible.
Agentweaver.Squad is only a runtime input here. For casting, roster management, .squad/ serialization, naming, and memory import/export, see Team Casting — Deep Dive.
The runtime mental model
An Agentweaver run is not simply "send a prompt to a model." It is a controlled workflow around a model turn:
- Prepare an isolated workspace so the agent can change files without directly mutating the source branch.
- Assemble identity and context from the selected agent charter, task, project memory, active decisions, session context, and workspace boundaries.
- Create a provider-backed turn agent that knows how to speak to a model provider and stream results.
- Expose tools through a governed tool plane so the model can inspect, edit, ask questions, report intent, and record memory without bypassing policy.
- Stream normalized events so the UI, persistence layer, watch loop, review gates, and coordinator can reason about the run without knowing provider internals.
- Persist the work and observations by committing workspace changes, computing a diff, running review/RAI/Scribe steps, and exporting memory when appropriate.
The important design choice is that model execution is treated as one node inside a broader workflow. The model decides what to do next, but the runtime decides what context it receives, which tools exist, whether an action is allowed, how output is observed, and how the run advances.
Package responsibilities
| Area | Conceptual responsibility |
|---|---|
Agentweaver.AgentRuntime | Owns the live turn agents, provider adapters, workflow executors, sandbox governance, run-event emission, review/RAI/Scribe integration, and Agentweaver loopback API tools. |
Agentweaver.AgentTools | Defines the canonical tool contracts as AIFunctions and the per-run context they need: workspace, sandbox root, executor, redactor, approvals, options, event hooks, and question gates. |
Agentweaver.Squad | Supplies runtime inputs such as agent identity, charters, team membership, decisions, and memory artifacts. The runtime consumes these inputs but does not own team casting. |
The packages are intentionally separated so tool contracts can remain provider-neutral while the runtime decides how each provider sees and governs those tools.
Where this lives:
packages/Agentweaver.AgentRuntimepackages/Agentweaver.AgentToolspackages/Agentweaver.Squad
The life of a run
A run begins in the API layer, but its core shape is runtime-driven:
- Reserve the run. The API validates the task, repository/project, branch, model preference, and optional
agent_name. It creates a durable run record before work begins. - Resolve the working area. The orchestrator creates or reuses a worktree. Coordinator child runs can share a parent worktree so subtasks collaborate on one branch instead of creating isolated branches that later conflict.
- Resolve the agent identity. Project runs validate that the requested agent exists in the team and load that agent's charter. The charter is part of the system context, not an implementation detail.
- Compile context. Runtime context is ordered so durable decisions and memory precede the current task. Child worker runs receive narrower context to reduce leakage and keep subtasks focused.
- Start a workflow. The workflow wraps the worker turn with surrounding nodes: review, merge, RAI, Scribe, and coordinator-specific paths when needed.
- Watch and persist. A watch loop listens to workflow and runtime events, translates them into UI-visible status, persists history, and handles terminal states.
Why this shape?
- The run must be restartable. Workflows and provider sessions can be checkpointed or reconstructed, so long-running runs survive process boundaries better than a single in-memory method call.
- The model must not own policy. The model can request a shell command or file edit, but governance, approvals, and sandbox boundaries are enforced outside the model.
- The UI needs provider-neutral events. A Copilot stream, a Foundry chat loop, a tool denial, and a review gate all become normalized run events.
- Post-processing is part of correctness. A useful agent run is not complete when the model stops talking; Agentweaver still needs a diff, commit, review state, RAI verdict, and memory pass.
Where this lives:
apps/Agentweaver.Api/Runspackages/Agentweaver.AgentRuntime/Workflowpackages/Agentweaver.AgentRuntime/CopilotAIAgent.cs
Agent turn loop
A turn is one bounded attempt by an agent to satisfy a task in a workspace. The turn loop has five conceptual phases.
1. Setup: build the run-scoped execution environment
The turn agent is configured per run, not globally. Setup receives the working directory, repository root, run id, model id, stream writer, project id, agent name, system context, and cancellation token. From those inputs it builds:
- a provider session configuration;
- a deterministic session identity tied to the run;
- a system prompt containing the base runtime instructions plus charter/memory context;
- sandbox policy and the selected command executor;
- file/search/edit helper objects scoped to the workspace;
- tool context and tool catalog;
- a permission handler that mediates native provider operations;
- an event emitter that can write normalized
RunEvents.
This phase intentionally disables provider-side config discovery for the live Copilot path. The runtime wants a controlled tool surface; it should not accidentally load arbitrary local MCP servers, skills, or config from the repository.
Invariant: anything that can affect tool access, workspace location, prompt context, or event output must be derived during setup and reset between runs. A reused agent instance must not leak event state, permission state, or registered tool names from a previous run.
2. Start or resume the provider session
The live Copilot worker uses a provider SDK session. If a workflow resumes, the runtime can deserialize the provider session state; otherwise it creates a fresh session. This is why the live worker implements serialization hooks. Ephemeral built-in reviewers such as RAI and Scribe intentionally do not need durable session state because they run short, single-purpose turns.
Trade-off: preserving provider session state improves continuity and checkpointing, but it couples the live worker to provider-specific serialization. Agentweaver hides that coupling behind the workflow turn-agent interface.
3. Stream model execution
The runtime sends the task into the provider session and consumes streaming updates. During streaming it emits:
- configuration snapshots such as selected sandbox backend and registered tools;
- the task and effective system prompt metadata;
- assistant token deltas;
- tool call, result, and error events;
- special semantic events such as
agent.intentandrun.outcome; - terminal turn events.
The runtime also retries known recoverable provider failures such as token refresh or rate-limit cases. It does not change the task semantics during retry; it simply attempts to complete the same turn.
Invariant: every observable action should produce stable, ordered events. Tool results must not appear before their call. Denials must not be silent. A degraded run must emit run.degraded before the run appears terminal to clients.
4. Mediate tool use
The model may request file reads, edits, shell commands, URL fetches, API tools, or custom functions. The runtime classifies the request, evaluates policy, and either allows execution or returns a denial.
For Copilot live runs, native provider operations are governed through the permission-request callback. This lets Agentweaver use provider-native file/shell capabilities while still applying Agentweaver policy. For registered custom functions, the runtime can decide whether to suppress raw tool lifecycle events and emit more meaningful domain events instead.
For Foundry, the runtime runs an explicit loop: send chat history and tool definitions, receive function calls, evaluate governance, invoke the matching function, append the function result to chat history, and continue until no calls remain or the turn limit is reached.
Invariant: the model only sees string-like tool results. This keeps the tool contract simple and portable across providers.
5. Close the turn and hand control back to the workflow
When the provider has no more work for the turn, the executor collects the assistant response, commits workspace changes, computes the diff, counts steps, and returns a structured turn output. The workflow then decides whether to proceed to review, ask for revision, merge, run RAI, run Scribe, or finish.
Trade-off: committing at the turn boundary creates a clear audit point and diff, but means each turn must be treated as an atomic unit of work. Multi-turn revision is modeled as additional workflow edges rather than hidden continuation inside the provider loop.
Where this lives:
packages/Agentweaver.AgentRuntime/CopilotAIAgent.cspackages/Agentweaver.AgentRuntime/Workflow/AgentTurnExecutor.cspackages/Agentweaver.AgentRuntime/Workflow/IWorkflowTurnAgent.cs
Runner selection and provider seams
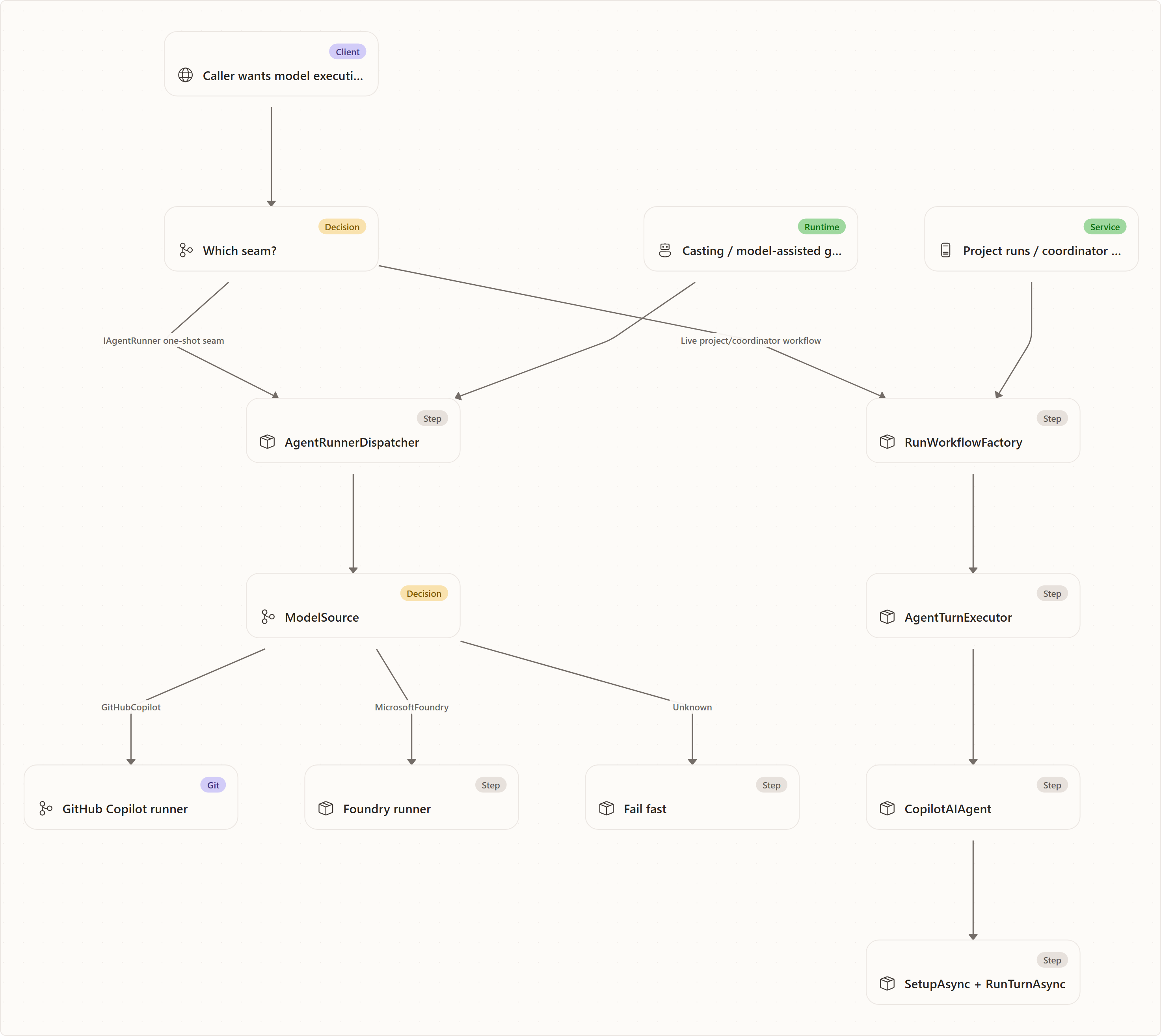
Agentweaver has two provider seams that are easy to confuse.
Seam 1: the one-shot runner dispatcher
IAgentRunner is a provider-neutral interface for "execute this task in this directory with this model source." The dispatcher chooses a concrete runner from ModelSource:
GitHubCopilotroutes to the GitHub Copilot runner.MicrosoftFoundryroutes to the Foundry runner.- unknown providers fail fast.
This seam serves one-shot, model-assisted tasks. The casting service is its primary caller: roster generation and other single-prompt operations run through this dispatcher. Foundry is wired here and runs whenever a caller reaches the dispatcher with MicrosoftFoundry.
Seam 2: the live workflow turn-agent seam
Project and coordinator runs are Microsoft Agents Framework workflows. The app-level live path is RunWorkflowFactory → AgentTurnExecutor → CopilotAIAgent: the workflow factory builds a Copilot-backed workflow turn agent, and the executor calls SetupAsync and RunTurnAsync on that worker. This path does not dispatch on AgentTurnInput.ModelSource to select Foundry.
This is the key nuance:
The dispatcher can route to Foundry, but the live project/coordinator run path builds the Copilot workflow agent. Foundry is wired behind the dispatcher, not selected by the app-level live workflow factory.
Why keep both seams?
- The dispatcher is simple and provider-neutral. It is a good adapter for operations that only need "prompt plus workspace plus result."
- The workflow turn-agent seam supports checkpointing, structured workflow edges, review loops, RAI/Scribe nodes, and provider session state.
- Keeping Foundry behind the dispatcher allows provider choice for one-shot operations without forcing live workflows to support all provider-specific session behavior.
Foundry's conceptual loop
Foundry does not use the Copilot SDK's native permission callback. Its runner owns the tool loop directly:
- Build chat history with the system prompt and user task.
- Register the full sandbox tool catalog as chat tools.
- Ask the model for the next assistant response.
- If the response contains function calls, normalize aliases, evaluate governance, invoke allowed functions, and append results.
- Repeat until the model stops calling tools or a maximum turn count is reached.
This makes Foundry easier to reason about as a classic tool-calling loop, but it means the runner must implement details that Copilot delegates to its SDK.
No app-level live run path selects Foundry through the workflow factory: the live project and coordinator path always builds the Copilot workflow turn agent. External callers that invoke IAgentRunner directly can still exercise the Foundry dispatcher path.
Where this lives:
packages/Agentweaver.Domain/IAgentRunner.cspackages/Agentweaver.Domain/ModelSource.cspackages/Agentweaver.AgentRuntime/AgentRunnerDispatcher.cspackages/Agentweaver.AgentRuntime/FoundryAgentRunner.cspackages/Agentweaver.AgentRuntime/GitHubCopilotAgentRunner.cspackages/Agentweaver.AgentRuntime/Workflow
Tool model
Tools are the runtime's contract with the model. A tool is not just a method; it is a named capability with a schema, description, result contract, policy context, and event behavior.
Why tool context is per-run
The same tool name can mean different concrete authority in different runs. read_file in one run must be scoped to that run's worktree, while run_command may be disabled, sandboxed, or approval-gated depending on run options. For that reason, tools are built from a SandboxToolContext rather than from global singletons.
A run-scoped tool context contains the facts a tool needs to make safe decisions:
- agent identity and run id;
- working directory and sandbox root;
- command executor and whether it provides real isolation;
- file/search/edit helpers restricted to allowed roots;
- output redaction;
- shell/network/destructive-command options;
- approval predicates and question gates;
- event hooks for user-visible progress.
Invariant: tools should not rediscover authority from process state. They should receive authority explicitly through context.
Canonical sandbox tools
The canonical catalog covers a small set of capabilities:
| Capability | Conceptual purpose |
|---|---|
read_file | Let the model inspect known files. |
file_search | Let the model discover paths by glob-like patterns. |
grep_search | Let the model find text without reading the whole repository. |
str_replace_editor | Make precise edits when the old text is known. |
apply_patch | Apply structured multi-file patches. |
create_file / write_file | Create or overwrite files when the runtime allows it. |
run_command | Execute commands through the selected sandbox/direct executor, subject to shell policy and approval. |
report_intent | Let the agent announce what it is about to do in a UI-friendly way. |
report_outcome | Let the agent declare whether the task was achieved and why. |
ask_question | Let the agent request human input through a controlled gate instead of stalling silently. |
run_command is conditional. It only exists when shell execution is enabled and the selected executor mode is acceptable for the run. This avoids advertising a capability the runtime will never allow.
Copilot live tool exposure
The live Copilot path intentionally does not register the entire sandbox catalog as custom functions. Instead:
- provider-native file operations (
view/read, write,str_replace_editor,grep,glob) are allowed to exist, but every operation is mediated by the permission handler, which enforces working-directory containment; - provider-native shell is not allowed. The SDK's native shell executes in-process and never routes through
ISandboxExecutor/bubblewrap — the permission handler can only see the working directory, not the command text or per-command filesystem confinement. The handler therefore rejects every native shell request for every run (not just Assembly Build/Test), and shell is exposed solely through the sandboxedrun_commandcustom function, which runs the command through the selected sandbox/direct executor andShellCommandValidator; - selected custom functions such as intent/outcome/question are registered because they represent Agentweaver-specific semantics;
- Agentweaver API tools are registered when the run has project and agent identity;
- raw lifecycle events for some semantic tools are suppressed and replaced with higher-level events such as
agent.intentorrun.outcome.
run_command is conditional: it is registered only when the executor provides real isolation (or direct mode) and shell policy is enabled. When shell is disabled there is no shell path at all — native shell is denied and run_command is absent — which is the intended fail-closed behavior.
This design avoids duplicate/conflicting file tools while keeping Agentweaver governance in front of native provider operations and ensuring all shell execution passes through the sandbox executor.
Foundry tool exposure
Foundry receives the full canonical sandbox catalog as function tools. Because Foundry does not have the same native permission callback, the runner performs the whole loop explicitly: map the requested function name, check governance, invoke the function, convert the result to text, and append it to chat history.
Agentweaver API tools
Agentweaver API tools are runtime-owned loopback tools, not sandbox file tools. They let agents interact with project state through the same API surface humans and MCP clients use.
Common project-agent tools include:
- submit a decision to the inbox;
- record memory;
- update the current session;
- list decisions and pending inbox entries;
- read memory;
- export memory artifacts.
Coordinator runs receive additional coordination tools because they manage plans and child work. Regular workers should not get coordinator-only authority.
Trade-off: loopback API tools make agents first-class participants in project memory, but they must be scoped by project id, agent name, API base URL, and API key. Without those boundaries, a tool call could affect the wrong project.
Human-in-the-loop tools
Some actions require a human or external decision:
- shell commands may require approval globally or when they match destructive patterns;
- URL fetches can be approval-gated;
ask_questioncan pause on a question gate and resume with the answer.
API-hosted runs persist shell approvals/denials, tool-approval context, approval/denial decisions, run-scoped and always-allowed policies, parent-child approval inheritance, pending questions/answers, and run options such as auto-approve and autopilot as ordered run events. The API registers durable IShellApprovalStore, IToolApprovalGate, IQuestionGate, and IRunOptionsStore implementations after the runtime defaults, so a worker on one replica can wait while an operator click, answer, or toggle lands on another replica.
The tool should always produce a useful result even when the gate is unavailable or times out: either a denial, a fallback instruction to use best judgment, or an explicit explanation. Silent blocking is not acceptable.

Where this lives:
packages/Agentweaver.AgentToolspackages/Agentweaver.AgentRuntime/AgentweaverApiTools.cspackages/Agentweaver.AgentRuntime/SandboxGovernance.csapps/Agentweaver.Api/Runs/DurableToolApprovalGate.csapps/Agentweaver.Api/Runs/DurableQuestionGate.csapps/Agentweaver.Api/Runs/DurableShellApprovalStore.csapps/Agentweaver.Api/Runs/DurableRunOptionsStore.csapps/Agentweaver.Api/Runs/DurableRunControlState.cspackages/Agentweaver.AgentRuntime/InMemoryQuestionGate.cs
Governance and sandboxing
The runtime assumes model output is untrusted intent. A requested command or edit is not safe just because the model produced it.
Governance answers three questions:
- Is the capability available? For example, shell execution may be disabled entirely.
- Is the target in bounds? File operations should stay inside allowed repository/workspace roots.
- Does the action need approval or denial? Destructive commands, broad shell access, URL fetches, and native tool requests can require explicit approval or fail closed.
The sandbox executor is the mechanical side of this policy. It determines where commands run and whether execution has real isolation. The governance layer is the decision side. The event stream is the observability side.
Important invariant: denial is a successful policy outcome, not an internal failure. The agent and UI should see that the attempted action was blocked, why it was blocked, and whether the run is now degraded.
Trade-off: stricter fail-closed behavior improves safety but can reduce agent autonomy. Agentweaver mitigates this by surfacing denials as context the agent can adapt to, rather than hiding them.
Where this lives:
packages/Agentweaver.AgentRuntime/SandboxGovernance.cspackages/Agentweaver.SandboxExecpackages/Agentweaver.AgentTools/Tools/RunCommandTool.cs
Event emission
Events are the runtime's shared language. They decouple provider-specific streaming from the rest of Agentweaver.
A useful event stream must provide:
- ordering: sequence numbers increase monotonically for a run;
- correlation: tool results and errors refer back to tool calls;
- semantic compression: noisy provider internals can become domain events like
agent.intent; - durability: live streams can be mirrored into persistent history;
- terminal clarity: clients should know when a turn ended, when a run degraded, and when workflow nodes completed.
The Copilot live agent therefore emits both low-level and high-level events: token deltas, tool calls, tool results, tool errors, sandbox selections, warnings, system prompt metadata, task metadata, RAI verdicts, Scribe status, and run outcome signals.
The runtime is careful about event timing. If a tool denial happens near the end of a turn, run.degraded is flushed before the terminal turn/run events so a live client does not render a clean success while missing the warning.
Where this lives:
packages/Agentweaver.AgentRuntime/CopilotAIAgent.cspackages/Agentweaver.AgentRuntime/Workflow/WorkflowStepEvents.csapps/Agentweaver.Api/Runs/RunWatchLoopService.csapps/Agentweaver.Api/Runs/RunWorkflowFactory.cs
RAI and Scribe touchpoints
RAI and Scribe are built-in agents that reuse the same Copilot-based turn machinery but serve narrow workflow roles.
RAI
RAI runs after the worker produces changes and before the work is treated as safe to ship. It receives the produced diff and reviews for security vulnerabilities, harmful content, PII exposure, and ethical concerns. Its verdict controls workflow behavior:
- GREEN: proceed.
- YELLOW: advisory warning; proceed with caution.
- REVISE: send actionable feedback back into the workflow so the worker can revise.
- RED: flag content safety and fail the RAI gate.
The verdict parser is intentionally defensive: it looks for explicit verdict markers rather than treating any mention of a word like "red" as a verdict. If RAI fails or returns an unparseable response, configuration decides whether to fail closed or proceed with an advisory warning.
Scribe
Scribe runs after a project run reaches a terminal state. Its role is memory hygiene, not code generation. It reviews what happened, records durable learnings or patterns, updates session context, and exports memory artifacts. Scribe failures are non-fatal to the completed run; they should be visible, but they should not turn a finished worker run into a failed one.
Scribe uses the same loopback API tool model as other agents, but its charter narrows authority: manage memory, merge/archive/export as appropriate, and do not make product/design decisions on behalf of the worker.
Where this lives:
packages/Agentweaver.AgentRuntime/RaiAIAgent.cspackages/Agentweaver.AgentRuntime/ScribeAIAgent.cspackages/Agentweaver.AgentRuntime/Workflow/RaiTurnExecutor.cspackages/Agentweaver.AgentRuntime/Workflow/ScribeTurnExecutor.cs
Squad touchpoints
The runtime consumes Squad data as context and routing input:
- project run submission validates that
agent_namebelongs to the active team; - the selected agent's charter is injected into the system context;
- project decisions and memories are compiled into prompt context;
- coordinator planning can assign work to real team members and dispatch child runs through the same runtime path.
The runtime should not know how to cast a team, name agents, or serialize the .squad/ directory beyond consuming the artifacts it needs. Keep that domain in Squad. See Team Casting — Deep Dive.
Where this lives:
apps/Agentweaver.Api/Endpoints/ProjectEndpoints.csapps/Agentweaver.Api/Runs/RunOrchestrator.csapps/Agentweaver.Api/Coordinatorpackages/Agentweaver.Squad
Rebuilding the runtime: design checklist
If you were rebuilding Agentweaver's runtime, preserve these design invariants:
- Separate workflow orchestration from provider execution. A model turn is a workflow node, not the whole run.
- Make provider selection explicit. Do not assume a model source string affects live workflows unless the workflow factory dispatches on it.
- Build tools per run. Tool authority must come from run context, not process globals.
- Govern before executing. File, shell, network, native, and API actions must pass policy outside the model.
- Return stable tool strings. Providers differ, but the model should receive simple, predictable tool results.
- Normalize events. UI and persistence should depend on Agentweaver event types, not provider SDK objects.
- Make denials observable. A blocked action should emit a tool error and, when appropriate, a degraded-run signal.
- Commit at boundaries. The workflow needs durable worktree state and diffs after turns.
- Keep memory explicit. Agents record decisions and memory through API tools; prompt context is compiled deliberately.
- Treat reviewers as agents with narrow charters. RAI and Scribe reuse the runtime but have constrained responsibilities.
Extension points and gotchas
Adding a tool
To add a provider-neutral sandbox tool:
- Define the tool name, input schema, description, and string result contract.
- Decide what run-scoped authority it needs and add that to the tool context if necessary.
- Add it to the canonical registry only if it should be generally available.
- Decide how each provider should see it:
- Foundry can receive it as a normal function tool.
- Copilot live may be better served by native provider capabilities plus permission handling, or by a selected custom function if the tool has Agentweaver-specific semantics.
- Add governance and event behavior before exposing it to the model.
Gotchas:
- Advertising a tool the runtime will deny every time trains the model badly. Prefer conditional registration.
- If the tool has side effects, denial and approval paths need first-class event output.
- Avoid returning complex provider-specific objects. Convert results into concise strings.
Adding a provider
To add a provider for the one-shot seam, implement the runner interface, register it, and update the dispatcher/model-source conversion.
To add a provider for live project/coordinator runs, that is not enough. You also need a workflow turn-agent implementation that supports setup, turn execution, event normalization, tool governance, and ideally session serialization. Then update the workflow agent factory to select it based on run input.
Gotchas:
- Foundry support in the dispatcher does not imply Foundry support in live workflows.
- New providers must preserve system-prompt context, memory instructions, and event semantics.
- If the provider has no native permission callback, the runner must own the tool loop explicitly.
Changing RAI or Scribe
RAI and Scribe are workflow safety/memory nodes, not general worker agents. Keep their charters narrow and their failure behavior explicit:
- RAI may block or request revision depending on verdict.
- Scribe should report failure but not invalidate an already-terminal worker run.
- Both should avoid long-lived session assumptions unless their workflow role changes.