
Data & Persistence — Conceptual Deep Dive
Purpose and Mental Model
Agentweaver persists more than rows in a database. It persists the state needed to coordinate long-running agent work, recover after restarts, explain why work happened, and safely turn isolated file changes into repository changes.
Think of the data layer as four cooperating persistence systems:
- Operational control plane — the authoritative record of projects, runs, workflow envelopes, backlog tasks, review revisions, cast proposals, and merge state.
- Memory and orchestration plane — decisions, draft decisions, agent memories, sessions, run-event history, coordinator plans, steering directives, and MCP OAuth state.
- Git state — branches and worktrees that hold the actual file changes produced by agent runs.
- Kubernetes storage lifecycle — persistent volumes, PostgreSQL Flexible Server, migration startup, and backups.
A rebuild should preserve the same separation of concerns: databases answer “what is the system state?”, git answers “what file state did this run produce?”, and exported .squad / .agentweaver files make selected memory visible to humans and agents.
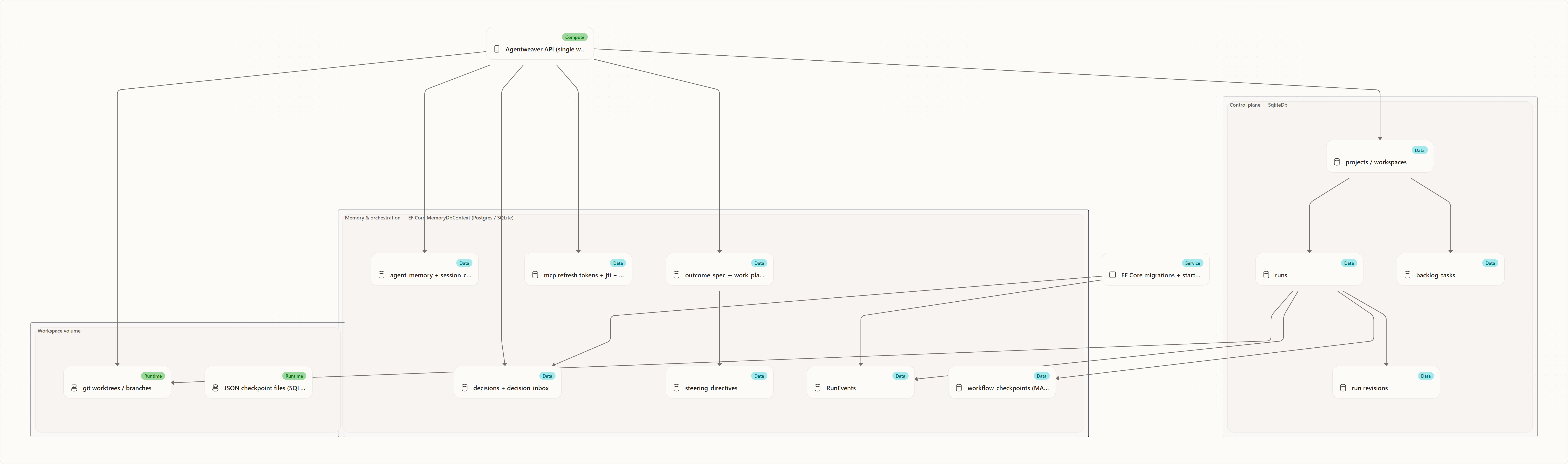
Architecture at a glance
The operational control plane lives in SqliteDb (projects, runs, backlog tasks, revisions); the memory and orchestration plane lives in EF Core (MemoryDbContext). Both stores are provider-aware: Database:Provider=Postgres routes everything through PostgreSQL Flexible Server (the AKS production deployment), while sqlite (the default for local dev) uses separate SQLite files. EF Core migrations manage the schema. Run worktrees live on the workspace volume. MAF JSON checkpoints are stored in the shared workflow_checkpoints table (Postgres) and fall back to JSON files on the workspace volume in SQLite/dev mode.
Design Goals
The persistence design optimizes for a single Agentweaver API instance coordinating many durable workflows:
- Recoverable runs: after a process restart, Agentweaver should know which runs exist, where their worktrees are, what status they were in, and what events already happened.
- Auditable decisions: durable team decisions and rejected/merged inbox items should explain the current operating rules.
- Safe isolation: unapproved agent changes should live outside the main branch until review and merge.
- Low operational burden for local dev: the SQLite provider avoids a database dependency when running locally.
- Replica-safe writes in production: the AKS deployment uses PostgreSQL Flexible Server with two API replicas. CAS-style
UPDATE ... WHEREguards status transitions; run-level leasing prevents double-dispatch across replicas. - Evolvable memory schema: the memory/orchestration model changes faster than the control-plane schema, so it uses EF Core migrations rather than hand-written SQL everywhere.
Local dev uses SQLite for simplicity. The AKS deployment uses PostgreSQL Flexible Server — this lifts the single-writer constraint and allows two replicas with a RollingUpdate strategy.
Conceptual Domain Model
Agentweaver’s durable domain has two halves: work execution and team memory.
Work execution concepts
- Project: a repository workspace plus its Agentweaver settings. It defines where work happens, which branch is default, who owns it, what model/provider defaults apply, which workflows are allowed, and what sandbox/review policies are active.
- Workflow run: a stable envelope for a user-submitted job. A workflow can create one or many child runs and may own a shared orchestration worktree.
- Run: one concrete agent execution. It records the prompt/task, model choice, submitting user, status, timestamps, worktree path, worktree branch, produced tree hash, diff, merge result, parent/child linkage, retry origin, and archive state.
- Backlog task: a project-scoped unit of future work. It can move from backlog to ready to claimed, and a claimed task points to at most one run.
- Run revision: immutable review feedback against a run. Revisions are append-only because they are part of the audit trail.
- Run event: an ordered event in a run’s stream. Events power live UI updates and restart-safe replay.
Team memory and orchestration concepts
- Decision: an accepted rule or fact for the project. Architectural and scope decisions become “boundaries” and outrank other memory.
- Decision inbox entry: a proposed decision, learning, pattern, or update. It remains durable whether merged or rejected, so the team can audit why something did or did not become policy.
- Agent memory: reusable context associated with a named agent. Some entries are private to that agent; entries tagged
cross-teamcan be injected into other agents’ context. - Session context: the current work focus for a project. It captures active issues, summary, and serialized state. At most one session should be considered “current” for a project.
- Outcome spec / work plan / subtask / dependency: coordinator planning records. They describe what successful completion means, how the work was decomposed, how subtasks depend on each other, and how assembly/recovery should proceed.
- Steering directive: human guidance injected into an active coordinator workflow.
- MCP OAuth state: refresh tokens, revoked JWT IDs, and dynamic client registrations needed for MCP authentication flows.
Database architecture
Production (PostgreSQL Flexible Server)
The AKS deployment uses Azure Database for PostgreSQL Flexible Server (Database:Provider=Postgres). Both stores — the operational control plane and the memory/orchestration plane — are unified behind a single EF Core MemoryDbContext and a single database. There is one connection string, one migration mechanism, and no local disk dependency for application state.
This removes the single-writer constraint. The deployment runs two API replicas; Postgres handles concurrent writes safely because every status transition uses a CAS-style UPDATE ... WHERE status = expected and run-level leasing ensures exactly one worker executes a given run at a time.
Local development (SQLite)
In local/dev mode (Database:Provider=Sqlite, the default), Agentweaver uses two SQLite files:
agentweaver.dbfor stable operational state (projects, runs, backlog tasks, revisions).memory.dbfor memory, orchestration, run events, and OAuth state.
This split is intentional. The control-plane store is hand-written SQL and conservative; the memory/orchestration plane evolves more quickly and benefits from EF Core's model relationships and migrations. Keeping it in a separate file avoids coupling EF migrations to the ADO.NET store. A single local writer means SQLite's simple transaction model is sufficient — no distributed coordination is needed.
SQLite is a good fit for local development because:
- One writer at a time; no concurrency configuration needed.
- WAL mode allows readers and one writer to coexist.
- Database files are easy to inspect and reset between tests.
- No external dependency to install or configure.
Operational Store: agentweaver.db
The operational store is the source of truth for the run control plane. If rebuilding Agentweaver, design this database around state transitions and invariants, not around object persistence.
It should hold:
- Projects: repository/workspace identity and project-level defaults.
- Runs: lifecycle state, worktree metadata, results, tree hashes, diffs, merge conflicts, review wait accounting, parent/subtask links, retry provenance, and archive state.
- Workflow runs: durable envelopes around user-submitted workflows, including shared orchestration worktree metadata.
- Backlog tasks: ordered project work items, claim state, and run linkage.
- Run revisions: immutable review feedback history.
- Cast proposals: persisted casting proposals that should survive API restarts.
- Token usage records (
token_usage_records): one row peragent.turn.usageevent, storingrun_id,workflow_run_id,project_id,model_id,input_tokens,output_tokens,total_tokens,total_nano_aiu, and a UTC timestamp. Enables efficient aggregation at run, workflow-run, project, and app levels without scanning the raw event payload columns. Schema added inapps/Agentweaver.Api/Infrastructure/SqliteDb.cs; also backed by an EF Core entity inapps/Agentweaver.Api/Infrastructure/Ef/EfTokenUsageStore.cs.
Consistency model
Operational writes should be small, explicit, and guarded by invariants:
- Run status changes are controlled transitions, not arbitrary updates. Merge and review flows rely on compare-and-set style behavior so two actors do not advance the same run inconsistently.
- Backlog claiming is atomic: moving a task into a claimed state and reserving the associated run must happen together or not at all.
- A backlog task can point to at most one run. This prevents duplicated execution for the same claimed task.
- Active backlog order keys are unique per project/state for unclaimed work, so ordered board operations remain deterministic.
- Run revisions are append-only. Review comments are evidence and should not be silently edited or deleted.
- Worktree metadata is durable before work begins. If the process restarts, the system can find or recreate the run’s worktree from stored path/branch data.
Migration approach
The operational database uses a bootstrap-and-patch model:
- Create missing tables if they do not exist.
- Apply idempotent schema changes for newer columns or indexes.
- Ignore “already exists” outcomes where safe.
This model is simple and robust for additive SQLite changes. Its trade-off is that complex schema refactors require extra care because there is no full migration history table for this store.
Where this lives: apps/Agentweaver.Api/Infrastructure, packages/Agentweaver.Domain.
Memory and Orchestration Store: memory.db
memory.db is named after memory, but it is broader than that. It stores human/team memory, durable run events, coordinator planning, steering directives, and MCP OAuth state.
It should hold:
- Decisions and decision inbox entries.
- Agent memory and session context.
- Run events for replayable streams.
- Outcome specs, work plans, subtasks, and subtask dependencies.
- Steering directives.
- OAuth refresh tokens, revoked JWT IDs, and MCP client registrations.
Why EF Core here?
The memory schema is relational and evolves frequently. EF Core gives this side of the system:
- explicit entity relationships;
- indexes for common project/status/agent lookups;
- migrations with history;
- a path to SQL Server or PostgreSQL for this database when deployment needs outgrow SQLite;
- simpler transactional code for inbox promotion and planning updates.
PostgreSQL is the production provider. SQLite remains the default for local development. SQL Server is also a supported EF provider for the memory store.
Core invariants
A rebuild should preserve these rules:
- Decision inbox slug uniqueness is project-wide. The same slug should identify one proposed item within a project regardless of agent.
- Rejected inbox items are retained. Rejection is a status transition, not deletion.
- Merging an inbox entry is transactional. Creating the accepted decision, linking the inbox row, and marking it merged must succeed together.
- Decisions can supersede decisions. Supersession keeps old decisions explainable while establishing the new active rule.
- Session IDs are unique per project. The “current” session is the most recent non-ended session.
- Tags are normalized with delimiter semantics. Tag filters depend on matching whole tags, especially
cross-team. - Subtask dependencies restrict deletion of depended-on subtasks while allowing a work plan to cascade-delete its owned subtasks.
- OAuth token and client identifiers are indexed/unique where replay or duplication would be unsafe.
Migration approach
The EF database uses normal EF migrations. In production, an init container runs the migration bundle before the API container starts, and the API also runs migrations during startup. This gives two safety nets: schema is prepared before normal serving, and an already-started API can still apply any pending migrations in development or nonstandard deployments.
A migration-history guard keeps EF startup deterministic when a database already has memory tables but lacks the expected EF history marker. It seeds the marker, creates the missing run-event table, and then lets normal migrations continue.
Where this lives: apps/Agentweaver.Api/Memory, apps/Agentweaver.Api/Migrations, apps/Agentweaver.Api/Program.cs.
Durable Run Event Streams
Run events are persisted in the database, not just kept in memory. The design is a two-layer stream:
- Durable write-through: append the event row to the database (Postgres in production, SQLite in dev) and assign/record its run-local sequence number.
- Live fan-out: publish the same event to an in-process channel for active subscribers.
The ordering matters: an event is written to the database before subscribers can observe it. That means a client may miss a live channel message, but it should not miss the event permanently.
Subscribers use a replay-then-tail pattern:
- Create or find the live channel.
- Replay persisted rows after the caller’s cursor.
- Tail the channel.
- Skip any channel event already delivered during replay.
- Stop cleanly after terminal event types.
The live channel is bounded. If a subscriber is slow or absent, live copies can be dropped; durability is still preserved by the database. This is the key design trade-off: the channel optimizes latency, while the database guarantees recovery.
The essential invariant is unique (run_id, sequence). It makes replay deterministic and lets clients resume from “last event I saw.”
Where this lives: apps/Agentweaver.Api/Infrastructure/SqliteRunEventStream.cs (SQLite/dev), apps/Agentweaver.Api/Memory/EfRunEventStream.cs (Postgres/production).
Decisions, Memory, and Context Assembly
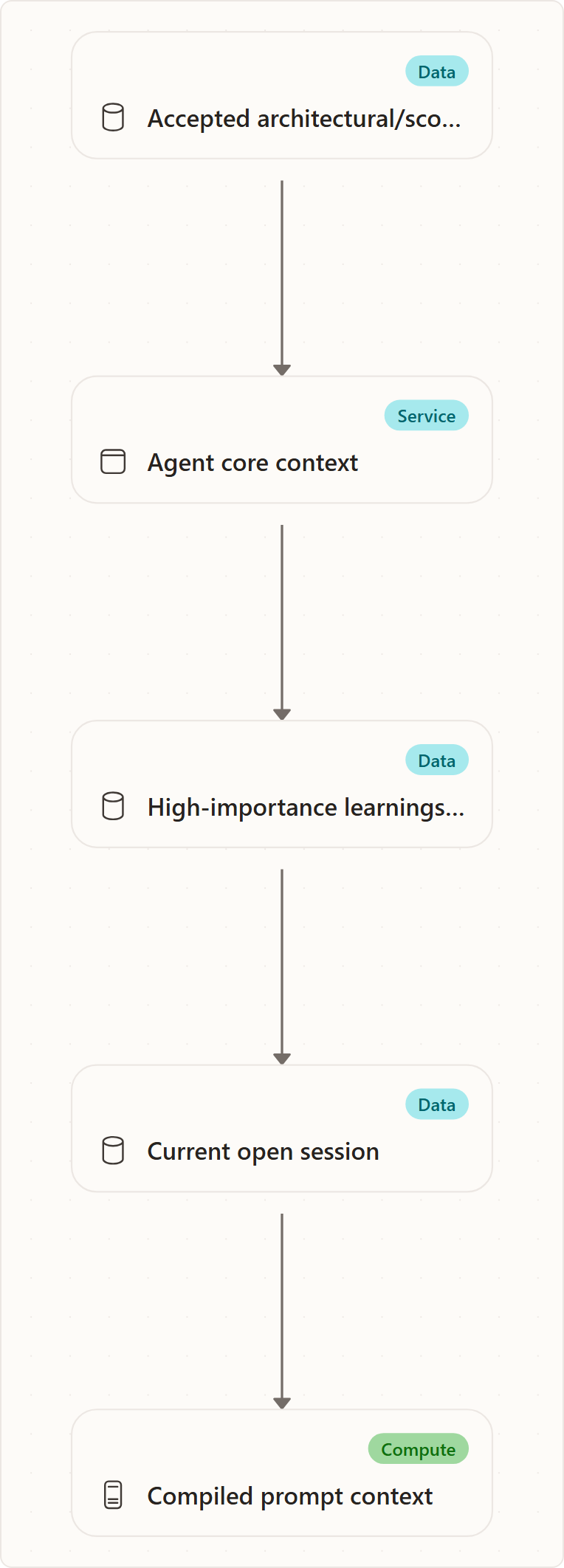
The memory layer is not a generic note store. It is a priority-ordered context compiler for agents.
The compiler builds context in this order:
- Active architectural and scope decisions — rendered as non-negotiable boundaries.
- Agent core context — durable charter-like information for the target agent.
- High-importance learnings and patterns — selected for the target agent, plus cross-team memories shared by tag.
- Current open session — focus area, active issues, and summary.
This ordering is the most important conceptual rule. Decisions are first because they constrain all work. Session context is last because it is useful but should not override boundaries or durable agent knowledge.
Decision inbox logic
The inbox is a review buffer between “an agent observed something” and “the team accepts this as durable policy.”
- Agents can submit proposed decisions, learnings, patterns, and updates.
- Pending entries remain visible for review.
- Promotion creates an accepted decision and marks the inbox entry merged.
- Rejection preserves the entry for audit.
- Routine learnings/patterns/updates can be auto-merged by the post-run scribe; architectural and scope boundaries should remain more review-oriented.
This prevents every agent thought from becoming policy while still preserving potentially valuable observations.
Memory selection logic
Agent memory has two audiences:
- Targeted memory: injected only for the named agent.
- Cross-team memory: injected for other agents when explicitly tagged for sharing.
Selection is bounded by item count and approximate token budget. Rebuild this as a deterministic selection problem: score by importance, prefer newer items where scores match, and stop before exceeding the budget. This keeps prompts useful and bounded.
Sessions
A session is the durable “what are we doing right now?” record for a project. Starting a new session ends older open sessions. Updating a session changes focus, active issues, summary, serialized state, or marks it ended. The compiler uses the most recent open session.
Export/import mirror
The database (Postgres in production, SQLite in dev) is authoritative for API reads, but selected memory is mirrored to files so humans and agents can inspect it in the workspace:
.squad/decisions.mdfor accepted decisions;.squad/decisions/inbox/{slug}.mdfor pending inbox entries;.squad/agents/{agent}/history.mdfor agent history;.squad/identity/now.mdfor current session focus;.agentweaver/context/boundaries.mdfor architectural/scope boundaries;.agentweaver/context/patterns.mdfor reusable patterns.
Export runs after memory mutations and after the post-run scribe pass. Import reads inbox files and creates missing pending rows. Treat files as a human/agent-facing mirror, not as the primary database.
Where this lives: apps/Agentweaver.Api/Memory, apps/Agentweaver.Api/Endpoints, packages/Agentweaver.Squad/Memory.
Git as Persistent Run State
Agentweaver does not store file changes in the database. It stores metadata in the database and lets git store the actual content graph.
For a normal run:
- Create a branch for the run from the originating branch.
- Check out that branch in a dedicated worktree.
- Persist the worktree path and branch on the run before agent work starts.
- Let the agent modify files inside that isolated worktree.
- Commit the result and persist the produced tree hash/diff.
- Merge only after review/approval and safety checks.
This provides strong isolation: unreviewed changes are real git changes, but they are not on the main project branch.
Revisions
A revision reuses the existing run worktree and branch. That is intentional: reviewer feedback should apply on top of the prior candidate result, not start from scratch unless the run is retried as a new run.
Coordinator shared worktrees
Coordinator workflows have a different isolation rule. Child runs can share the coordinator’s orchestration worktree so one child can read files produced by another child. The database stores the shared worktree path on the workflow/coordinator metadata so orchestration can resume or recover.
The trade-off is explicit: ordinary runs maximize isolation; coordinator child runs allow controlled collaboration inside a shared workspace.
Merge consistency
Merge is guarded by both database state and repository locking:
- acquire a repository-level merge lock;
- transition the run into a merging state;
- verify the approved tree hash still matches what is being merged;
- detect idempotent already-merged cases;
- update the target branch safely;
- persist the merged commit hash and terminal status;
- remove the worktree on success;
- preserve the worktree and conflict list on merge failure.
The tree hash check is important: it binds human approval to a specific file tree. Without it, a worktree could change after approval but before merge.
Recovery
Worktree metadata may outlive the physical directory. This can happen if the database and git branch remain but the worktree folder is removed. The recovery path should prune stale git worktree administration data and recreate the worktree from the persisted branch.
Where this lives: apps/Agentweaver.Api/Git, apps/Agentweaver.Api/Runs, apps/Agentweaver.Api/Infrastructure.
Kubernetes Storage
The production deployment uses one persistent volume for filesystem state:
agentweaver-workspace: ReadWriteMany, mounted at/workspace. It holds project workspaces, git worktrees, and the shared home directory (/workspace/.home).
All application state (runs, projects, memory, events, OAuth) lives in Azure Database for PostgreSQL Flexible Server, provisioned externally. Use Azure's built-in automated backups and point-in-time restore for data protection.
Where this lives: k8s/base/api-deployment.yaml, k8s/base/pvc-workspace.yaml.
Rebuild Checklist and Invariants
If rebuilding Agentweaver’s data layer from these concepts, preserve these decisions first:
- Separate operational state from memory/orchestration state unless you deliberately migrate both to one coherent server database.
- Keep run lifecycle transitions explicit and guarded. Do not let arbitrary writes mutate terminal or merge states.
- Persist worktree path/branch before agent execution so in-flight work can be recovered.
- Use git for file content and the database for metadata. Do not duplicate large diffs as the only source of truth.
- Make review revisions append-only.
- Make run events durable before live publication and replay by sequence.
- Treat decisions as higher priority than all other memory.
- Keep inbox rejection/audit history rather than deleting rejected proposals.
- Bound memory injection by importance, recency, item count, and approximate prompt budget.
- Close older open sessions when starting a new session for the same project.
- Use repository-level locking and tree-hash verification for merges.
- Align deployment topology with database semantics: one SQLite writer on an RWO PVC, or move to a server database before scaling writers.
- Back up every authoritative database file. In the production deployment that means
agentweaver.dbandmemory.db, not just the operational database.
Common Gotchas
memory.dbis not just memory; it also holds run events, coordinator planning, steering, and OAuth state.- The two databases have different migration systems: hand-written additive schema setup for
agentweaver.db, EF migrations formemory.db. - SQLite WAL improves concurrency but does not make SQLite a multi-writer distributed database.
- File exports are mirrors. The API should read authoritative memory from SQLite.
- Child coordinator runs intentionally receive a narrower context than full agents: team boundaries and task-specific instructions matter more than bloating every child prompt with all memory layers.
- A missing worktree directory is recoverable only if the database metadata and git branch still exist.
- Successful merges clean up worktrees; conflicted merges preserve them for inspection.
- The backup CronJob covers
agentweaver.dbonly.
See also
- Token usage monitoring — Deep Dive — the
token_usage_recordsschema, projection service, and aggregation hierarchy.