
Frontend — Conceptual Deep Dive
Purpose and Mental Model
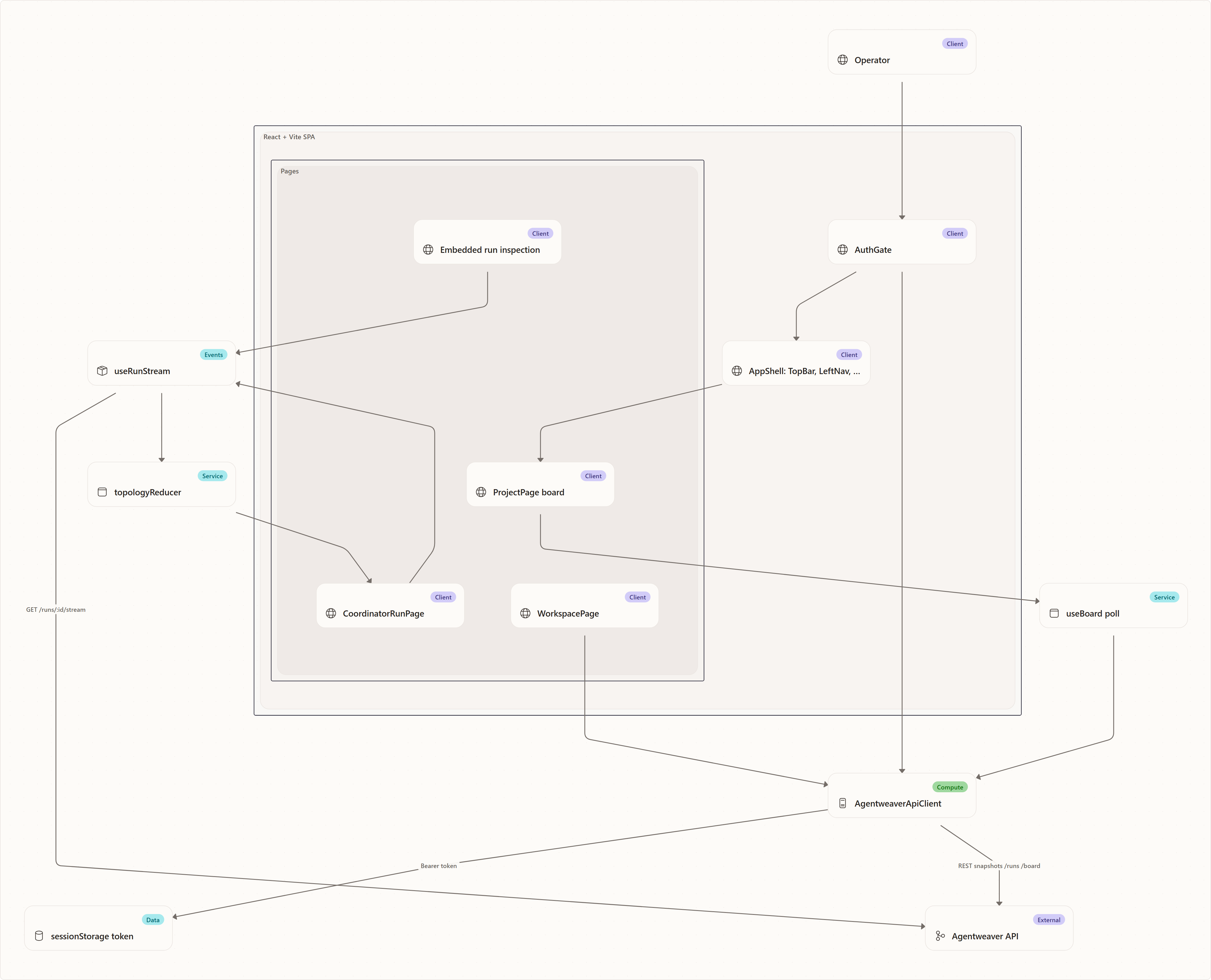
Agentweaver's frontend is a browser-based control room for agent work. It does not run agents, decide orchestration topology, or persist long-term state itself. Its job is to:
- authenticate the user,
- let the user choose a project and issue commands,
- ask the backend for authoritative snapshots,
- subscribe to live run events,
- fold those events into UI-friendly state, and
- render the current state clearly enough that a human can steer, approve, inspect, or recover work.
The most important rebuilding idea is snapshot + stream:
- Snapshots answer, "What does the backend know right now?" They come from REST calls and are used when a page first loads, when a completed run is reopened, or when the UI needs metadata such as project lists, teams, graph descriptors, work plans, files, and settings.
- Streams answer, "What changed after I started watching?" They come from Server-Sent Events (SSE) on a run stream.
- Reducers turn raw events into display models: timelines, run status, graph state, coordinator topology, approval cards, and child request lists.
This gives the UI a robust mental model: the backend is the source of truth; the frontend is a deterministic projection of backend facts.
Where this lives:
apps/web/apps/Agentweaver.Web/
Frontend Boundary
The frontend has three runtime layers:
- React/Vite SPA — the application the user interacts with. It owns routing, presentation, browser state, REST calls, SSE consumption, and UI projections.
- Agentweaver API — the authoritative backend. It owns projects, auth, runs, orchestration, work plans, event logs, files, reviews, and mutations.
- Static web host — a small ASP.NET Core app that serves the built SPA and docs. It is not a backend-for-frontend; it does not implement the API routes used by the SPA.
A rebuild should preserve that boundary. Avoid putting business decisions in the browser just because the browser has enough data to guess. For example, the coordinator graph is server-authored: the UI renders topology snapshots and deltas instead of recomputing dependencies on the client.
Trade-off: this makes the UI simpler and safer, but it means the backend must emit complete enough facts for the UI to render useful state.
Where this lives:
apps/web/src/apps/Agentweaver.Web/Program.cs
Technology Shape
The SPA is a TypeScript React app built with Vite. It uses React Router for browser routes, Fluent UI for the visual system, React Flow/Dagre for graph-like views, and Vitest/Testing Library for frontend tests.
The entrypoint mounts React into the #root element, wraps the app in React StrictMode, and uses a small error boundary so a render exception becomes a recoverable error screen instead of a blank page.
At the app root, the UI is wrapped in:
- a Fluent UI provider, so components share theme tokens,
- a browser router, so deep links are normal URLs,
- an auth gate, so protected app routes do not render until session validation completes,
- a persistent shell, so navigation and top-level context remain stable across pages.
Rebuild principle: keep the app root boring. Cross-cutting concerns belong there; feature behavior belongs in pages, hooks, reducers, and components.
Where this lives:
apps/web/src/main.tsxapps/web/src/App.tsxapps/web/package.jsonapps/web/vite.config.ts
Routing and Information Architecture
Routes are split into global destinations and project-scoped destinations.
Global routes do not require a project id:
- overview / now view,
- project gallery / project creation.
Project-scoped routes start with /projects/:projectId and represent the work surface for one project:
- dashboard,
- board,
- flow,
- orchestrations,
- workspace,
- settings,
- team / casting,
- memories,
- workflows,
- diagnostics / heartbeat,
- orchestration detail pages with embedded run inspection.
All signed-in routes sit inside the persistent shell. The shell is intentionally above individual pages because navigation, project switching, top bar status, and the floating orchestration action should not disappear when the user opens a deep orchestration page.
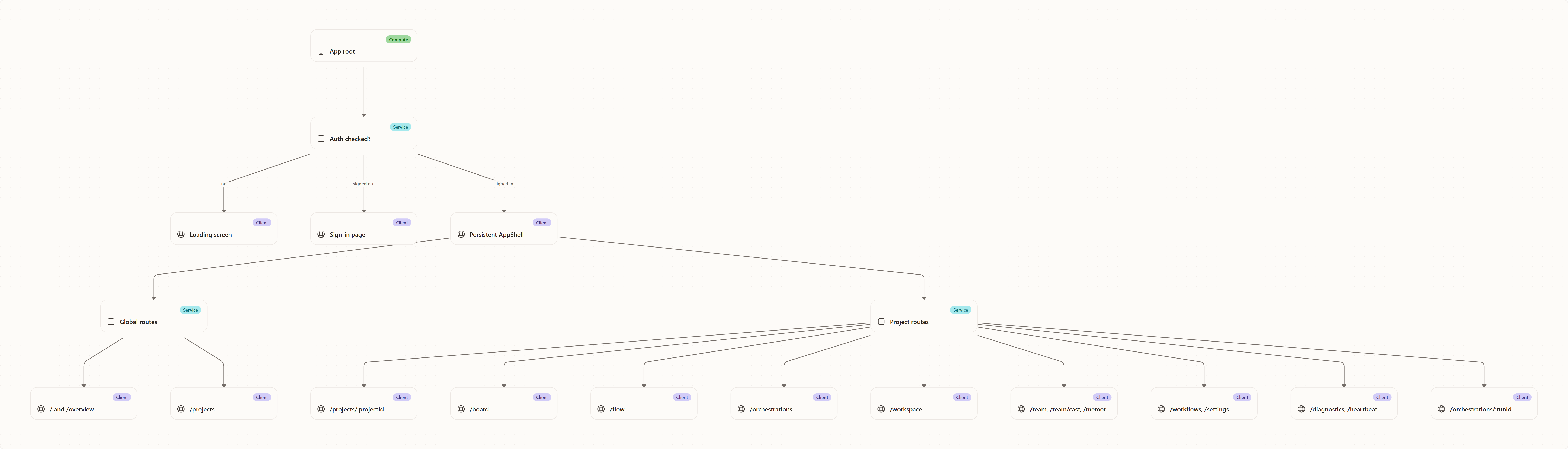
The shell derives the active project from the URL. When the user moves to a global page, it remembers the last active project in local storage so the project switcher and project-scoped navigation can still point somewhere useful. This is a UX convenience only; the route remains the source of truth for the currently displayed page.
Rebuild principle: routes should describe user intent, not implementation detail. An orchestration detail URL should be directly openable after refresh, and the page should be able to reconstruct its state from route parameters plus backend snapshots.
Where this lives:
apps/web/src/App.tsxapps/web/src/components/shell/
API Client Design
The frontend uses one conceptual API client: a typed wrapper around fetch. Each method describes a backend operation in application terms, while the private request layer handles shared mechanics:
- combine the configured base URL with a method path,
- attach session auth if present,
- include cookies for cookie-backed sessions,
- JSON-encode request bodies,
- parse successful JSON responses,
- throw a structured API error for non-OK responses.
The /api base URL convention
Important convention: the API client base URL may be /api, so individual client method paths must not include /api.
For example, the client should be configured with a base URL like /api, then methods should call relative API paths like /runs, /auth/github, or /projects/{id}/orchestrations. If a method includes /api itself, production builds would accidentally call /api/api/....
This convention is what lets the same SPA run in multiple environments:
- local development can point at
http://localhost:5000, - containerized production can point at
/api, usually through a reverse proxy or same-origin API route, - the bundle does not need to be rebuilt just because the API origin changes.
Why centralize API calls?
Centralization gives the app one place to solve auth, errors, request formatting, and response typing. Pages can stay focused on interaction flow: "create a run," "load graph," "approve review," or "list projects." It also makes conventions enforceable; a new endpoint should be added as a method that accepts application inputs and returns typed application data.
Trade-off: the API client can become large. Keep it organized around backend resource groups and avoid embedding page-specific UI decisions in it.
Where this lives:
apps/web/src/api/apiClient.tsapps/web/src/api/client.tsapps/web/src/api/types.tsapps/web/src/config.ts
Runtime Configuration and Static Hosting
The SPA is built once and configured at container startup. index.html loads /env-config.js before the React bundle. The container entrypoint writes window.__AGENTWEAVER_CONFIG__ with the API URL, defaulting to /api.
This design separates build-time artifacts from deployment-time configuration:
- Vite builds static JavaScript, CSS, and assets.
- The container decides where the API is at startup.
- The ASP.NET Core host serves the static files and docs.
- Non-HTML assets can be cached aggressively because their built filenames are content-addressed by Vite.
- HTML and fallback responses should not be treated as immutable because they bootstrap the current app version and runtime config.
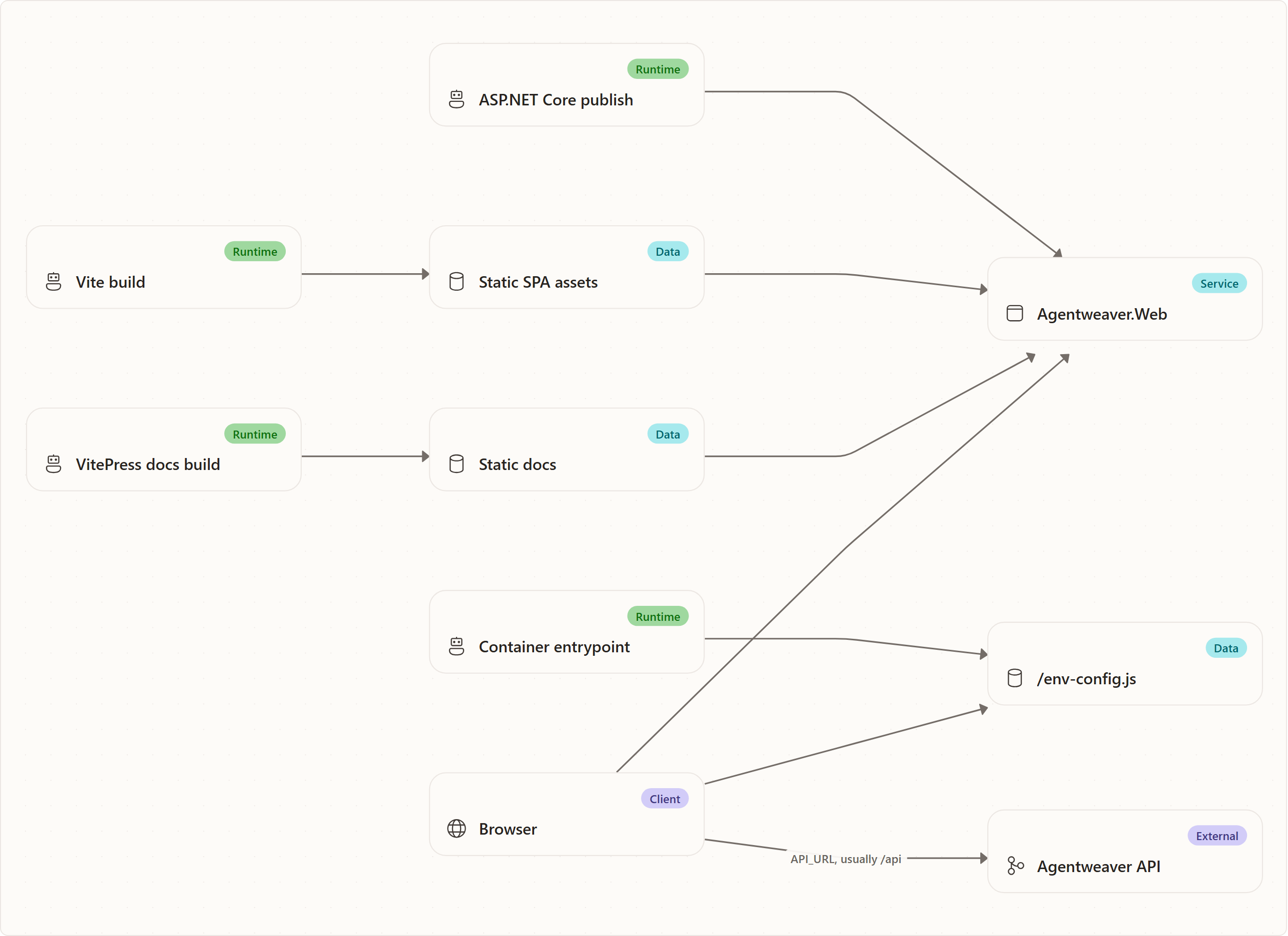
Rebuild principle: static hosting should be dumb and predictable. Let the API own API behavior; let the SPA own client behavior; let the host serve files and route unknown non-doc paths back to index.html for client-side routing.
Where this lives:
apps/web/index.htmlapps/web/Dockerfileapps/web/docker-entrypoint.shapps/Agentweaver.Web/Program.cs
Authentication and Session Flow
The UI starts in an auth gate. It does not render the signed-in shell until it has resolved any auth redirect and verified the current session with the backend.
Conceptually, sign-in works like this:
- The unauthenticated page sends the browser to the backend GitHub authorization endpoint.
- The backend completes the GitHub flow and redirects back to the SPA with a short-lived code marker.
- Before rendering protected routes, the auth gate exchanges that code for session information.
- The frontend stores the session token and login in
sessionStorage. - The API client sends the token as a bearer header when present and also includes cookies.
- The auth gate asks the backend for GitHub auth status.
- If the backend says the user is signed in, the shell renders. Otherwise, local session state is cleared and the sign-in page renders.
The stored login is not just display data. The auth gate compares it with the backend-reported login. If the browser has a token for one user but the backend session reports another, the UI clears local session state rather than silently mixing identities.
The top bar separately fetches auth status for avatar/login display and exposes sign-out. Sign-out calls the backend and returns the browser to the app root.
Trade-offs:
sessionStoragelimits token lifetime to the browser tab/session, which is safer than long-lived local storage but means new sessions must rehydrate from cookies or sign in again.- Sending both bearer auth and cookies supports multiple backend session mechanisms, but every request path must be careful to include credentials consistently.
- URL auth parameters are stripped after exchange so tokens/codes do not linger in browser history or copied links.
Where this lives:
apps/web/src/App.tsxapps/web/src/config.tsapps/web/src/pages/SignInPage.tsxapps/web/src/components/GitHubSignIn.tsx
State Management Philosophy
Agentweaver does not use a single global Redux-style store. State is scoped to the part of the UI that owns it:
- auth/session state lives in the auth gate and browser session storage,
- the project list lives in a small React context shared by shell components,
- the last active project lives in local storage as a navigation convenience,
- page-level forms and toggles live in local component state,
- run timelines and coordinator topology are derived from event streams through reducers,
- persisted backend state is reloaded through REST snapshots instead of being treated as browser-owned.
This keeps state lifetimes aligned with user workflows. A page can be remounted when the active project changes, forcing clean refetches. A deep orchestration page can be opened directly and rebuilt from snapshots plus the stream. A shell-level project switcher can share the project list without making every feature depend on a global app store.
Rebuild principle: store the minimum browser state needed for responsiveness and navigation. Anything authoritative should be fetched from, or streamed by, the backend.
Where this lives:
apps/web/src/hooks/useProjectList.tsxapps/web/src/components/shell/projectContext.tsapps/web/src/timeline/apps/web/src/state/topologyReducer.ts
Live Run Timeline: Event-Sourced UI Projection
The live run UI is the heart of the frontend. It treats a run as an ordered stream of facts.
A run can emit events such as:
- agent turn started / ended,
- message deltas and final messages,
- tool calls and tool results,
- shell/tool approval requests,
- workflow graph updates,
- sandbox warnings,
- review and merge lifecycle events,
- coordinator lifecycle events,
- subtask status changes,
- child questions or approvals,
- terminal completion/failure events.
The stream hook uses fetch, not browser EventSource. That is intentional: authenticated streams need custom headers such as Authorization, and replay after reconnect benefits from Last-Event-ID.
The hook keeps a bounded event buffer so a runaway stream does not grow the DOM forever. It recognizes terminal events so completed streams stop reconnecting. It uses reconnect backoff so transient network issues do not immediately fail the page.
Reconnect after coordinator confirmation
Coordinator runs pause the stream at the confirmation gate: when the run enters awaiting_confirmation, the backend closes the stream with a done event. At that point OutcomeSpecPanel fetches the latest spec directly from the REST API (fetchSpec()) so the panel always shows the persisted, authoritative spec rather than reconstructed stream state. The internal terminalRef is reset and reconnectKey is incremented, which causes useRunStream to re-open a fresh stream against the same run ID. When the user clicks Confirm, the frontend calls onReconnect(), which triggers the same reconnectKey increment and stream re-open. New coordinator events — work-plan creation, subtask dispatch, child run starts — start flowing immediately after confirmation without a manual page refresh.
The timeline reducer is pure: given prior timeline state and the next event, it returns the next display state. It groups messages into turns, pairs tool calls with results, surfaces approvals, tracks outcomes, and bounds large text fields. Because it is pure, the same event sequence should produce the same timeline whether it came live from SSE or from a persisted event log.
This is the key mental model: SSE events are not rendered directly. They are normalized into durable UI concepts.
Where this lives:
apps/web/src/api/sse.tsapps/web/src/timeline/apps/web/src/components/Timeline.tsxapps/web/src/pages/CoordinatorRunPage.tsx
Snapshot + Stream Synchronization
A live stream alone is not enough. Users frequently open pages after work has already started or completed. A completed run may no longer have an active stream. A coordinator topology snapshot may have been emitted before the browser connected.
Agentweaver solves this by layering data:
- REST seed — load the latest known snapshot or persisted event list.
- SSE stream — append newer live changes.
- Deduplication — avoid showing the same event twice, usually by sequence id.
- Reducer fold — derive display state from the merged event list.
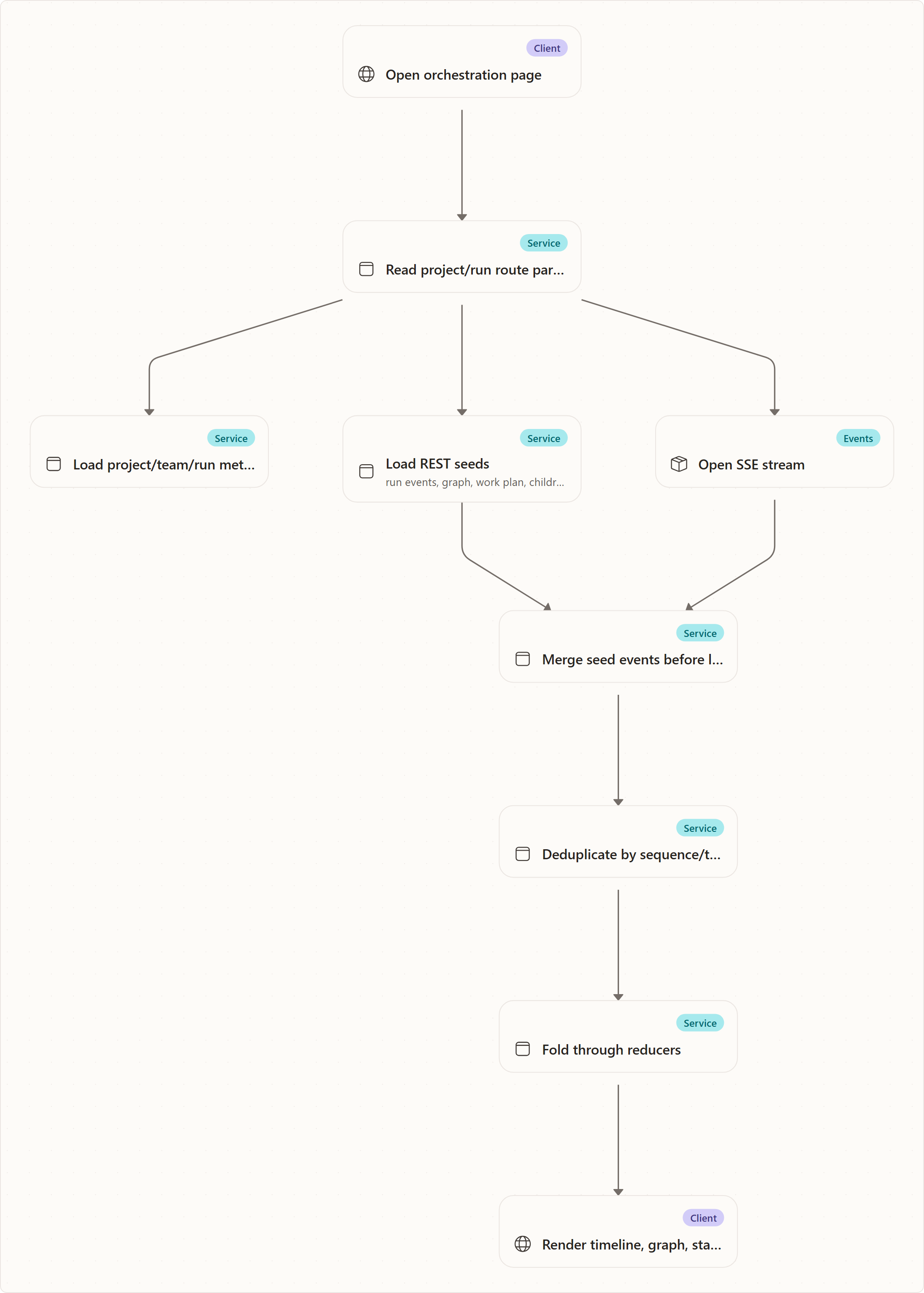
For embedded single-agent/child runs, the surface resolves run metadata, optionally fetches persisted events for terminal or parked states, fetches a graph descriptor when needed, and then merges live stream events over the seed.
For coordinator runs, the page loads graph/work-plan/children snapshots so the all-up graph and agent rail render immediately, then applies coordinator SSE events as live deltas.
Trade-off: merge logic adds complexity, but it gives a much better operator experience. Refreshing a finished run should not show an empty timeline just because the live stream has already closed.
Where this lives:
apps/web/src/pages/CoordinatorRunPage.tsxapps/web/src/api/sse.ts
Single-Agent Run Flow
A single-agent run is the simplest execution path:
- The user starts a run from a project surface, usually with a task, branch, and optional agent selection.
- The backend creates the run and returns identifiers.
- The run appears in project/coordinator surfaces.
- Embedded inspection resolves the run metadata and stream key.
- The surface loads any persisted seed events and graph descriptor.
- The surface opens the SSE stream.
- The timeline and graph update as events arrive.
- Review, request-changes, commit, and merge actions call the API and then refresh or reconnect the stream projection.
Run inspection is deliberately built from reusable pieces: timeline, graph/workflow panels, review controls, sandbox/files panels, and stream hooks. A rebuild should keep the stream/reducer logic independent from the visual layout so the same run projection can appear in different contexts.
Important edge case: coordinator child runs may not appear in the parent project run list because they are children, not top-level project runs. Embedded inspection can still resolve them directly by run id and treat that run id as the stream/graph key.
Where this lives:
apps/web/src/components/NewRunDialog.tsxapps/web/src/components/ReviewPanel.tsx
Coordinator Orchestration Flow
Coordinator mode is the multi-agent execution path. The frontend presents it as one orchestration, but internally it is a coordinator run plus child runs.
Conceptually:
- The user gives a goal.
- The coordinator drafts or confirms an outcome specification.
- The backend decomposes the goal into a work plan and topology.
- Subtasks are dispatched to child runs.
- Child runs emit their own events, questions, tool approvals, and terminal states.
- The coordinator stream re-projects the all-up lifecycle so the user can monitor and steer from one page.
- When children are ready, assembly/review/merge phases progress through coordinator events.
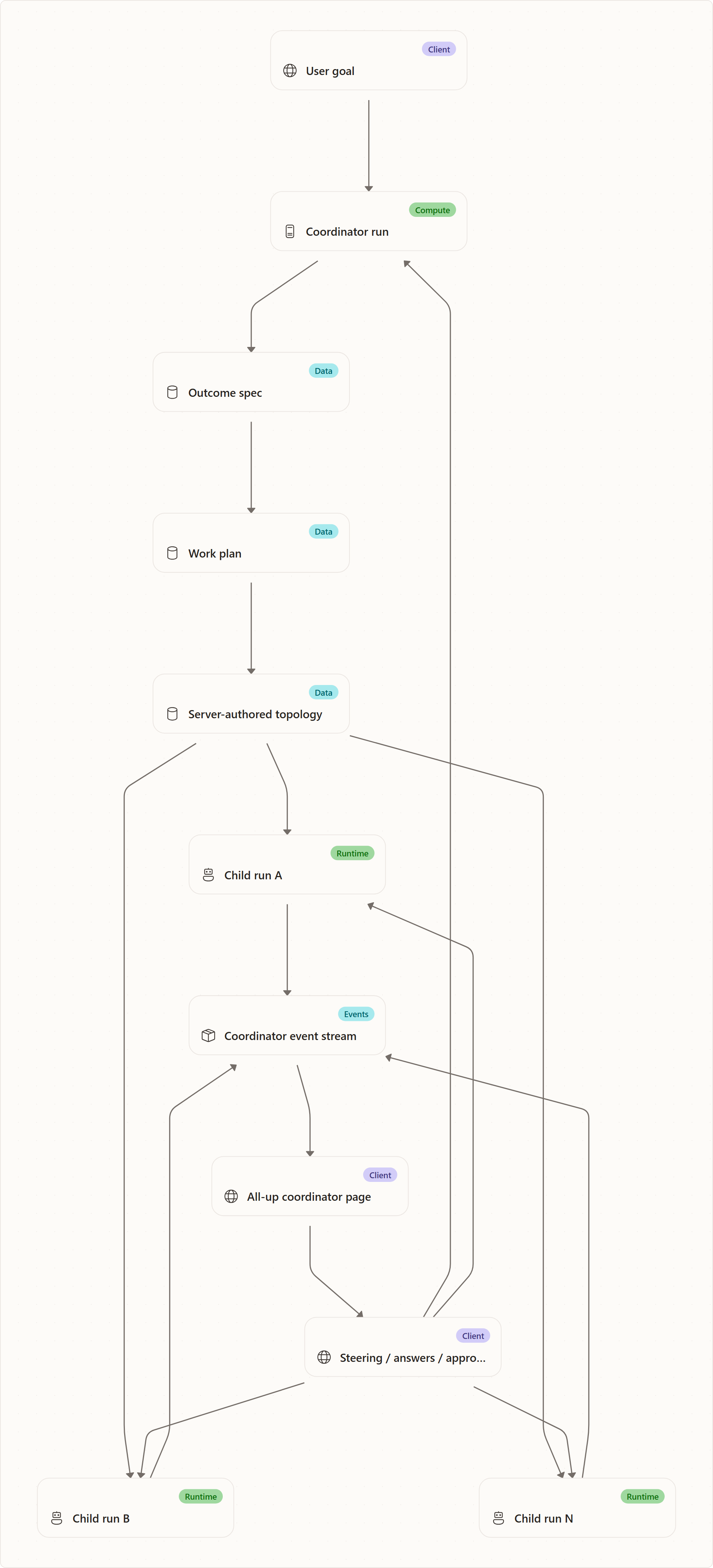
The topology reducer is intentionally thin. It applies server-authored snapshots and deltas, merges subtask status updates, and attaches steering state to existing nodes. It does not invent dependencies or compute topology from scratch. This protects the UI from accidentally disagreeing with backend scheduling rules.
Coordinator pages also need special handling for child questions and approvals. The user sees them in the all-up coordinator page, but the response must be sent to the child run that asked. Therefore each displayed request carries the child run id and, when available, the subtask id.
Automation toggles such as autopilot and auto-approve tools are shown at the coordinator level, but backend behavior may cascade them to children. The UI uses optimistic state for responsiveness and reverts on API failure.
Rebuild principle: show the user one orchestration, but keep run ownership precise. Coordinator commands go to the coordinator; child answers and tool grants go to the requesting child.
Where this lives:
apps/web/src/components/StartOrchestrationDialog.tsxapps/web/src/pages/CoordinatorRunPage.tsxapps/web/src/state/topologyReducer.tsapps/web/src/components/CoordinatorTopologyGraph.tsxapps/web/src/components/AgentRail.tsx
How the UI Stays in Sync
The UI stays in sync by following these rules:
- Use route params as identity. A page knows which project/run to load from the URL.
- Fetch snapshots on entry. Load enough REST data to render immediately, even for completed runs.
- Subscribe to the run stream. Open one SSE stream for the run currently being watched.
- Replay from the last event id. On reconnect, ask the backend for events after the last seen sequence.
- Deduplicate defensively. Streams, snapshots, reconnects, and singleton events can overlap.
- Fold, do not mutate ad hoc. Raw events become stable UI state through reducers and derived selectors.
- Let terminal events stop liveness. Completed/failed/merged/declined states should not reconnect forever.
- Treat backend snapshots as authoritative. Especially for coordinator topology, work plans, child ownership, and run status.
This pattern is close to event sourcing, but only on the client projection side. The frontend does not own the event log; it consumes the backend's event log and renders a projection.
Error Handling and Recovery
Frontend error handling is layered:
- render errors are caught by the root error boundary,
- API non-OK responses become structured client errors,
- auth failures clear local session and return to sign-in surfaces,
- stream failures reconnect with backoff where safe,
- missing optional snapshots are tolerated when the stream can still provide state,
- missing durable logs fall back to live SSE when available,
- terminal/parked runs use persisted events because no live stream may exist.
A rebuild should distinguish between fatal and non-fatal failures. Failure to fetch an optional graph descriptor should not prevent the timeline from rendering. Failure to validate auth should prevent protected routes. Failure to reconnect a run stream after repeated attempts should surface an actionable status rather than silently freezing.
Content and Safety Considerations
Timeline text is rendered as React text, not interpreted HTML. Large content fields are capped before being stored in timeline state to reduce unbounded DOM growth. Display helpers shorten noisy file paths in card headers while preserving fuller details where expansion is supported.
The important design principle is to make untrusted run output observable without making it executable. Agent and tool output should be treated as data.
Where this lives:
apps/web/src/timeline/reducer.tsapps/web/src/components/ToolCallCard.tsxapps/web/src/components/Timeline.tsx
Rebuild Checklist
If rebuilding the Agentweaver frontend from scratch, implement in this order:
- Static Vite React shell with routing and a root error boundary.
- Runtime config loader that can set API base URL at deployment time.
- Typed API client with centralized auth, credentials, JSON parsing, and API errors.
- GitHub sign-in handoff, session exchange, session validation, and sign-out.
- Persistent app shell with global/project navigation and project context.
- Project list/provider and project-scoped pages.
- Run stream hook using fetch-based SSE with auth headers,
Last-Event-ID, dedupe, terminal detection, and reconnect backoff. - Pure timeline reducer that folds raw events into display items.
- Embedded single-agent/child run inspection using REST seeds plus live SSE.
- Coordinator page using graph/work-plan/children seeds plus coordinator SSE.
- Thin topology reducer that applies server-authored snapshots and deltas.
- Review, approval, question-answering, and steering actions that call the correct owning run.
- Static hosting with SPA fallback and docs handling.
Gotchas and Conventions
- Do not prefix API client method paths with
/api; configure/apias the base URL and use relative paths such as/runsor/auth/github. - The static web host is not the API. It serves built files, docs, and SPA fallbacks.
- Runtime API URL should override build-time environment so one bundle can deploy to multiple environments.
- Use fetch-based SSE, not plain
EventSource, if authenticated headers and replay control are required. - Finished or parked runs need REST seeds because their live stream may already be closed.
- Coordinator topology is server-authored; render it instead of recomputing it.
- Child questions and tool approvals shown on the coordinator page must be answered against the child run that asked.
- Keep browser state small. Backend state is authoritative; UI state is a projection.